This blog post will give you an overview of how pdfHTML maps the HTML model onto the iText model, and how you can influence this process.
About the iText document model and Layout objects
To give you a quick idea of what our model stands for, hereby a quick overview of the key features:
-
it allows developers to quickly grasp how to use iText without having to understand the PDF specification.
-
it closely resembles HTML, and is based on how documents are formed structurally.
-
it is designed using concepts that most people can easily understand, such as paragraphs and tables.
During the design process for the iText 7 layout module, we noticed that there are a lot of similarities between the iText document model and the HTML model. For example, iText uses objects - such as paragraph and tables - to simplify the creation of PDF documents. HTML uses similar objects to let you construct HTML files.
Considering this overlap, we took a few ideas of the HTML model and implemented these into our model. Also, can the object models be easily mapped onto one another. We have tried to map every HTML tag - that makes sense in a PDF file - to our iText layout object. This is easy for some objects, for example: a span is still a span.
Nevertheless, there are a few HTML tags that don't make sense in the context of PDF, but most of these do correspond to an iText equivalent. They were a modified version of what we already implemented. For instance, an "article" tag is mapped onto a "div" element. The iText 7 layout model doesn't know the concept of an article, so we mapped the article onto a div. After all, when you squint your eyes, an article can be seen as a div under a different name. Some tags were not included because they were not relevant in a PDF, such as Audio.
This table gives you a brief overview of the default mapping we provided:
|
A |
ATagWorker |
|
Article |
DivTagWorker |
|
BDI |
SpanTagWorker |
|
BDO |
SpanTagWorker |
A technical overview of the mapping process
Let's have a look at how the mapping process is handled. In the diagram "Processing nodes" you can see how PDFHTML works.
There are 4 steps that pdfHTML goes through to make an iText layout object:
-
Create the layout object
The first step is the most obvious one: if an HTML tag corresponds to an iText Layout object then at one point you should make an iText Layout object. This is done through the ITagWorker interface. We'll dive into the TagWorkers later in this post. -
Process children
pdfHTML processes the tags depth-first: if this tag has any child tags it will loop over all the child tags and go through this flow again with the child tags before finishing the flow for the current tag. Meaning that if a child tag has more children, it will go over them as well, and so on. -
Apply the CSS
After processing the child tags, pdfHTML will apply the CSS to the iText Layout object. This is done through CSS Appliers. -
Return to the parent layout object
The Layout object is now complete. It contains its child elements and its CSS is also applied. This object will now be returned to its parent tag for further handling.
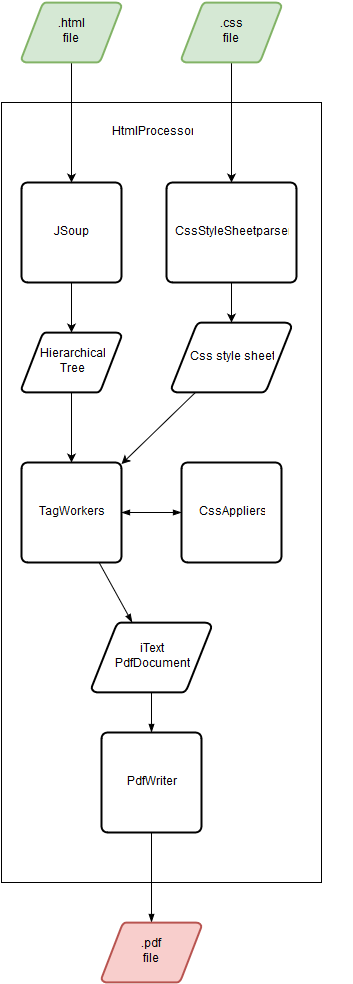
Figure 1: pdfHTML tag processing
ITagWorkers and ITagWorkerFactory
The actual processing of the HTML tags into iText objects happens in the ITagWorker implementations. We've provided standard implementations for every HTML tag we support. The mapping of HTML tags onto ITagWorkers happens in the ITagWorkerFactory. Our default implementation is the DefaultTagWorkerFactory and it can easily be extended to support your own tags.
It is important to know that for each tag the HtmlProcessor encounters, by default a new TagWorker instance will be created. So, when you're creating your own custom tags, do keep in mind that it was our intent to have no state in a TagWorker.
Customizing the mapping
While our set of tags is quite large and covers most needs, pdfHTML doesn't support every tag. Some tags are not relevant in a PDF context or maybe you added your own custom tags to your HTML files for processing purposes. You might want to process an unsupported tag and at least add some of its content to the output PDF. Or maybe you want to map every table tag onto a span object, just because you can.
Well, you can! pdfHTML allows for some very extensive customization concerning the mapping and there's a few options:
-
You can implement the ITagWorkerFactory interface.
-
You can extend the DefaultTagWorkerFactory and override the getCustomTagWorker method.
We always advise you to use the second option. This option allows you to take advantage of our own internal mapping we made. It also allows you to remap existing tags onto other ITagWorkers as the getCustomTagWorker method has priority over our internal mapping.
The following code sample maps everything onto a SpanTagWorker.
public class CustomTagWorkerFactory extends DefaultTagWorkerFactory {
@Override
public ITagWorker getCustomTagWorker(IElementNode tag, ProcessorContext context) {
return new SpanTagWorker(tag, context);
}
}
Don't try this at home! There are more useful things to do with a custom mapping.
customTagWorkers
Let's say that in our converted PDF files we want to insert a QR Code based on the data in our database. You could insert this data into the HTML in a custom tag:
1 2 3 4 5 6 7 8 9 10 11 | </p> <p>QRCode Example</p> <p>QR Code below,Q</p> <p>With great power comes great current squared times resistance</p> <p>QR Code below, L</p> <p>With great power comes great current squared times resistance |
For this tag to be picked we'll need to write a TagWorker. This class will parse and process the information inside the tag and its attributes.
QRCodeTagWorker
public class QRCodeTagWorker implements ITagWorker {
private static String[] allowedErrorCorrection = {"L","M","Q","H"};
private static String[] allowedCharset = {"Cp437","Shift_JIS","ISO-8859-1","ISO-8859-16"};
private BarcodeQRCode qrCode;
private Image qrCodeAsImage;
public QRCodeTagWorker(IElementNode element, ProcessorContext context){
//Retrieve all necessary properties to create the barcode
Map hints = new HashMap();
//Character set
String charset = element.getAttribute("charset");
if(checkCharacterSet(charset )){
hints.put(EncodeHintType.CHARACTER_SET, charset);
}
//Error-correction level
String errorCorrection = element.getAttribute("errorcorrection");
if(checkErrorCorrectionAllowed(errorCorrection)){
ErrorCorrectionLevel errorCorrectionLevel = getErrorCorrectionLevel(errorCorrection);
hints.put(EncodeHintType.ERROR_CORRECTION, errorCorrectionLevel);
}
//Create the QR-code
qrCode = new BarcodeQRCode("placeholder",hints);
}
@Override
public void processEnd(IElementNode element, ProcessorContext context) {
//Transform barcode into image
qrCodeAsImage = new Image(qrCode.createFormXObject(context.getPdfDocument()));
}
@Override
public boolean processContent(String content, ProcessorContext context) {
//Add content to the barcode
qrCode.setCode(content);
return true;
}
@Override
public boolean processTagChild(ITagWorker childTagWorker, ProcessorContext context) {
return false;
}
@Override
public IPropertyContainer getElementResult() {
return qrCodeAsImage;
}
private static boolean checkErrorCorrectionAllowed(String toCheck){
for(int i = 0; i
Because pdfHTML doesn't know about the QRCodeTagWorker, we'll need to plug it in into our custom DefaultTagWorkerFactory implementation:
public class CustomTagWorkerFactory extends DefaultTagWorkerFactory {
@Override
public ITagWorker getCustomTagWorker(IElementNode tag, ProcessorContext context) {
if ( "qr".equalsIgnoreCase(tag.name()) ) {
return new QRCodeTagWorker(tag, context);
}
return null;
}
}
Now, all we need to do it register this into the pdfHTML workflow:
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setTagWorkerFactory(new CustomTagWorkerFactory());
HtmlConverter.convertToPdf(
new FileInputStream("C:\\Temp\\qr\\qrcode.html"),
new FileOutputStream("C:\\Temp\\qr\\out.pdf"),
converterProperties);
Run this code sample and you'll get the following output:
Summary/Conclusion
Now that we've reached the end of this blog post, let's look at what we've learned of how pdfHTML:
-
The layout model has a lot of similarities to the HTML model, so mapping is relatively easy
-
pdfHTML iterates over the HTML structure depth-first to create its iText layout structure
-
You can extend or customize the mapping using ITagWorkers and ITagWorkerFactory
Try pdfHTML for yourself with a Demo or download and try it free for 30 Days with our Free Trial.


