pdf2Data for PDF processing
pdf2Data is a solution to easily recognize and extract data from documents in a structured, reusable format. It is available for Java and C# (.NET), Docker, and as a CLI version.
It offers a framework to intelligently recognize data inside PDF documents, based on selection rules that you define in a template. This offers significant advantages over AI-based alternatives which need extensive training to recognize documents.
And thanks to the intuitive browser-based pdf2Data Editor (also available as a Docker image), anyone, from marketers to information managers to HR staff, can create and update templates. You don't need to be a developer to benefit from using pdf2Data.
What is pdf2Data?
pdf2Data is our collaborative and user-friendly template-based solution for PDF data extraction.
pdf2Data consists of three modules:
- pdf2Data Manager,
- pdf2Data Editor,
- pdf2Data SDK.
These components cover all parts of the extraction process, from defining the desired information to be integrated into your workflow, maintaining and updating the parsing rules over time with strict access management, and the heavy lifting of high-volume document processing.
If your documents are not PDF, then iText has you covered. The iText add-on pdfOCR turns scanned documents and images into PDF (or PDF/A-3u if you need long-term archiving compliance) ready to be processed by pdf2Data.
Why use pdf2Data?
Data is an important commodity, and you may have more than you realize locked inside your PDF documents. Collecting this data manually could take a lot of time and resources, with the risk of input errors or security issues to consider.
With pdf2Data you can automate the data capture process and extract data in a secure way. By building a template from a single reference file, pdf2Data enables you to recognize and extract data from all PDFs which follow the same predictable format. This extraction approach provides you with the highest possible confidence level from the start, with no need for large datasets to train recognition models.
pdf2Data templates are flexible and reusable, so you don’t need to redefine extraction rules for each new document from scratch. Instead, you can easily reuse/modify existing templates to process documents with new or different layouts.

Fast and user friendly
pdf2Data reduces the time to unlock and reuse PDF data. Both the maintenance and updating of extraction rules is quick and easy with the pdf2Data Manager.
Using the pdf2Data Editor, simply define the desired information you want to extract in a template, which can be immediately used in production by the pdf2Data SDK.
Suits any documents with a predictable structure
Whether you have invoices, forms, purchase orders, bank statements, reports… Don’t worry.
If you can predict relations inside your documents, you can process PDFs in your workflow.
Simple integration
pdf2Data uses open standards to facilitate integration, which makes integrating it into existing workflows easy and fast. It includes developer-focused SDKs for Java and .NET (C#) as well as a command line interface, and now a Docker image with a REST API. PDF data processing for the 21st century.

Better than AI-based alternatives?
Since the content recognition is based on extraction templates you define, pdf2Data requires no prior training to recognize and extract data. The data recognition uses a number of rules, which need to be defined in advance for each data field. Typical rules use all details from the PDF document, and can be combined to help ensure accurate and valid data extraction.
Core capabilities of pdf2Data
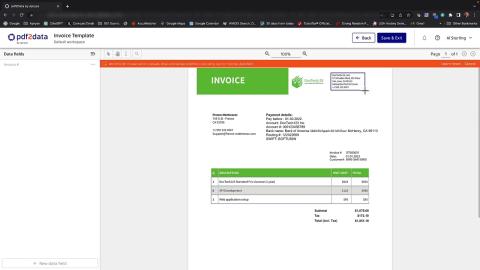
pdf2Data works by defining the areas, fonts, patterns, or tables of interest in a template that is used for all PDFs created in the same format, such as an invoice or other commercial documents.
You then can define areas of interest with data field selectors. Each selector uses a different way of identifying the information that is important. Selectors can also be combined to fine-tune the data identification and capture depending on your requirements.
The data is output in a structured, reusable format for further processing, with access to the page coordinates of the extracted content.

Extract data from PDF documents
Leverage iText's high-fidelity content extraction for recognition of text, images, and other content.
Intuitive extraction configuration
pdf2Data has comprehensive out of the box functionality, with the flexibility to extend and customize. Focus on easy integration and open standards.
Use templates to streamline extraction
Define areas of interest and selection rules to get exactly the content you need.
Integrate in your PDF and/or data workflow
Data is output in a structured, reusable format for further processing, with access to the page coordinates of the extracted content.
What pdf2Data does
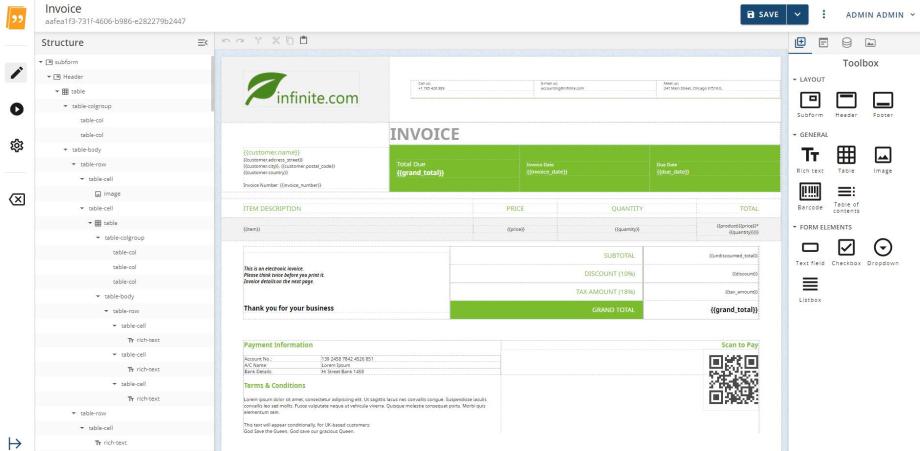
Many PDF documents businesses need to process, such as registration forms, invoices etc. follow a common structure. If we take the example of an invoice document, the invoice number, supplier address, purchase order number and similar document elements tend to be located in one place, and only the content such as item descriptions, quantities and cost of items change from invoice to invoice. By using an example invoice as a template, it is possible to define areas of the document where the data you want to capture is located and categorize it.
pdf2Data offers an easy way to extract data from such PDF documents by defining areas and rules in a template which correspond to the content you want to extract. The template can then be visually validated with other documents to confirm data is recognized correctly, before being parsed by the pdf2Data SDK to process all subsequent documents matching that template.
Unlike AI-based alternatives, you don’t need hundreds of samples and intensive supervision to train the recognition process. The content recognition is controlled by the template you configure, meaning no training is required before you can begin extracting data. You only need one example document to enable data extraction from all subsequent documents.
AI recognition has other disadvantages too. Any changes to the required output (such as adding a new field) will require models to be retrained, and multiple language support is minimal at best. Documents using the same layout but containing content in different languages can give wildly inconsistent results.
pdf2Data on the other hand suffers from none of these drawbacks. Making modifications to templates is quick and easy, and it offers excellent language support. It also provides powerful table recognition functionality, which is one of the primary shortcomings of other data extraction solutions.
How pdf2Data works
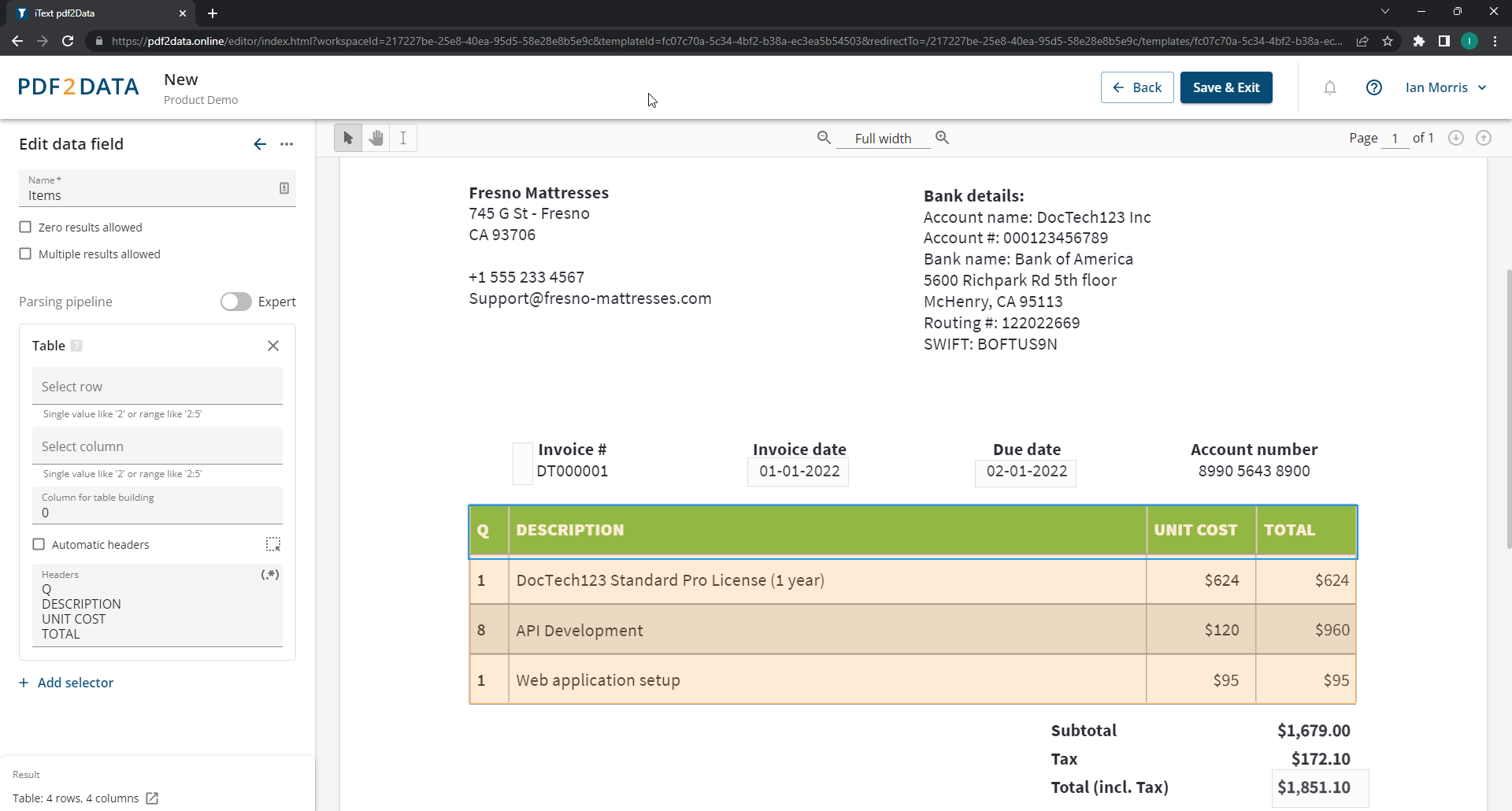
By using the intuitive browser-based pdf2Data Editor, it’s easy to create a template for data extraction. Simply create a template PDF based on a sample document, by defining data field selectors for areas of interest. Selectors are configurable rules to detect different types of content for extraction.
There are approximately two dozen selectors to choose from which enable pdf2Data to intelligently recognize and extract text, and other content such as images or barcodes. The selectors can be configured to detect:
- page range and the position on the page
- specific font styles, font color, and text patterns
- fixed keywords next to the data
- automatic recognition of table structures
In addition, many selectors can be combined to fine-tune the detection parameters.
Your extraction template will then be used to parse all future PDFs matching the template. Using the pdf2Data Editor, you can upload a document to test your extraction template and make sure the data field selectors are configured correctly to recognize the data you require.
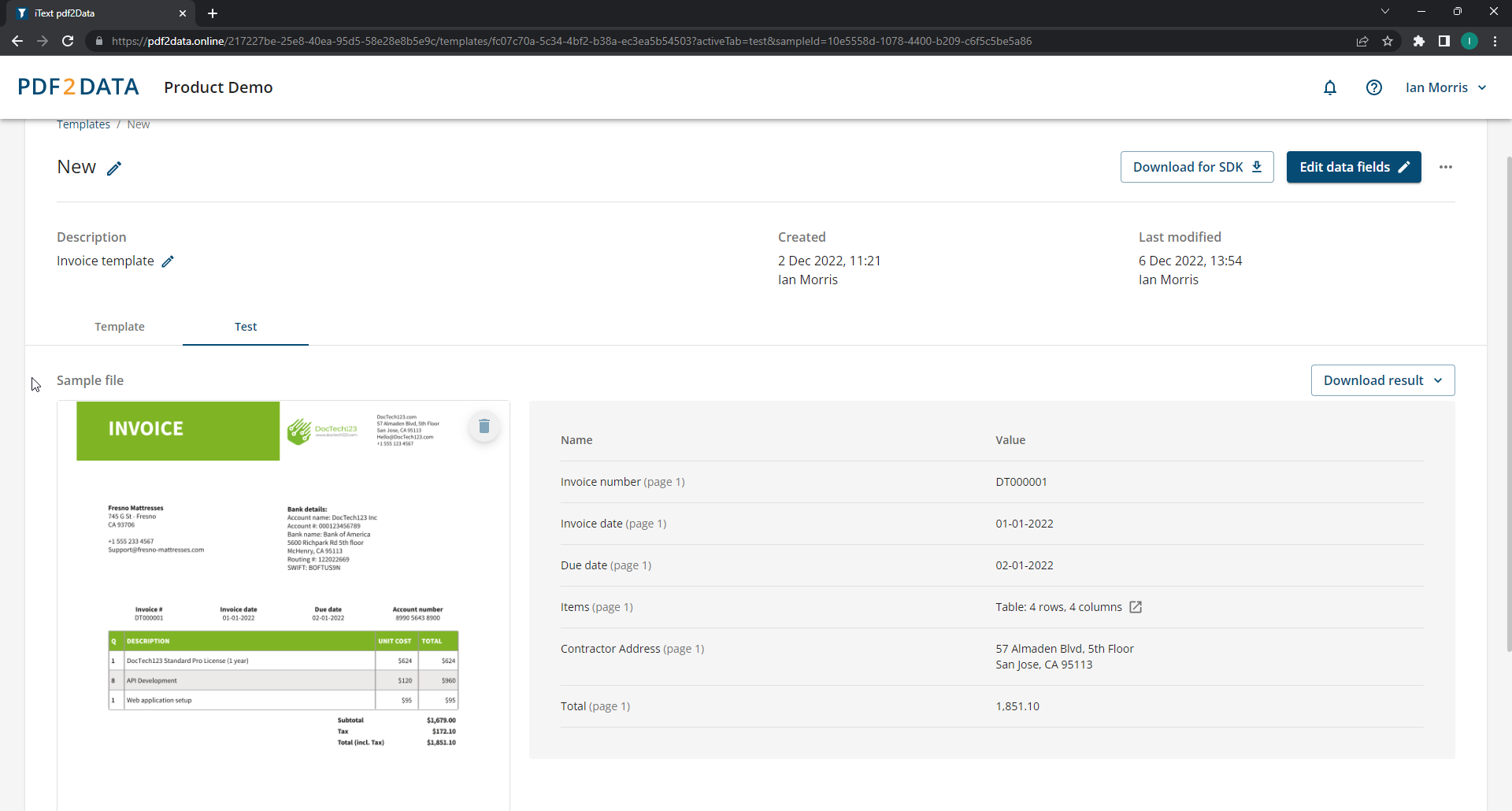
Similar to our document generation solution iText DITO, pdf2Data allows anyone to leverage iText's powerful PDF capabilities, not just developers. It's simple to create or refine document templates to recognize and automatically extract data, which can then be easily reused by whoever needs it. By intelligently extracting data from documents in a smart and structured way, the data can easily be repurposed for analysis, reports, or whatever you want.
Developers are only needed to deploy the pdf2Data Manager/Editor and integrate the pdf2Data SDK into your document workflow. From then on, you can configure a template, verify the data, and set pdf2Data to work.
You can find installation instructions, tutorials, and detailed documentation for all data field selectors in our Knowledge Base.
Resources
Here you will find the needed resources to install, configure and use the pdf2Data components. If you’re looking for a demonstration of how pdf2Data works, make sure to request a demo where you can get a guided presentation of its functionality.
Other resources
Now you have the data extracted, insert it in a template-based solution
That's template-based data extraction done and dusted. Are you interested in a template-based, collaborative solution to create PDFs from data?