We are thrilled to kick off a new year by announcing our latest data extraction release - pdf2Data 4.4. This version is focused on two major areas: enhancing user experience and refining data extraction capabilities. It is key to eliminating data silos and enabling users of all skill levels to make data-driven decisions.
How pdf2Data Can Streamline Your IDP Workflows
Many businesses need to access and reuse data trapped inside PDFs, such as invoices, statements, or contracts. Recent years have seen the rise of Intelligent Document Processing (IDP) solutions, typically relying on AI or machine learning to recognize and process documents. However, such approaches require extensive training to accurately identify documents, which can be time-consuming and expensive.
In contrast, our pdf2Data solution uses a template-based approach which requires only a single example PDF to get started. Since documents such as invoices from a common supplier will have a standardized layout with only the content changing, pdf2Data allows you to collaboratively build, manage, and reuse extraction templates for specific document types.
With pdf2Data, you can easily automate the extraction of content from PDFs and transform it into reusable, structured data. Using the wide range of selectors, you can quickly build a parsing pipeline to find and extract useful data in documents. Selectors are available to intelligently identify specific text, barcodes, dates, and even multi-page tables.
Thanks to pdf2Data’s flexible and on-premises deployment, integration into existing document workflows can be seamlessly and securely achieved. With convenient Docker deployment and a RESTful API in addition to native Java and .NET libraries, pdf2Data has comprehensive cross-platform compatibility, whatever your infrastructure.
In short, pdf2Data can save your business precious time and boost the productivity of modern IDP-focused workflows by easily allowing data in PDFs to be accessed and repurposed.
Enhanced and Intuitive User Experience
Our goal has always been to make data extraction as seamless and code-free as possible so that any authorized user can use pdf2Data with little to no IT requirements. With this release, we are doubling down on that commitment.
Users can now set up even more complex extraction pipelines in the pdf2Data Editor by using new predefined rules and selectors which require minimal to no coding skills to make full use of. Templates can then be used by the pdf2Data Parsing Engine to process your documents, and enable more efficient automated IDP workflows.
Mixing and matching selectors is especially beneficial for extracting data from documents with complex structures or formatting, and as with all pdf2Data 4.x releases, we’ve focused on further improving the access to selector functionality previously only available in expert mode. Let’s take a closer look.
More Intuitive Data Extraction
With pdf2Data 4.4, we’ve taken a significant leap in data extraction technology. The new release offers:
- Advanced Parsing: The ability to handle more complex documents with ease, thanks to the new selectors.
- Improved Recognition Results: We’ve revised the format of pdf2Data’s recognition results to be more logical and consistent across the different Parsing Engines and JSON/XML output formats. Data fields have been streamlined so that the results are more predictable and grouped results have also been improved. The new format also allows easier introduction of new result types and selectors in the future.
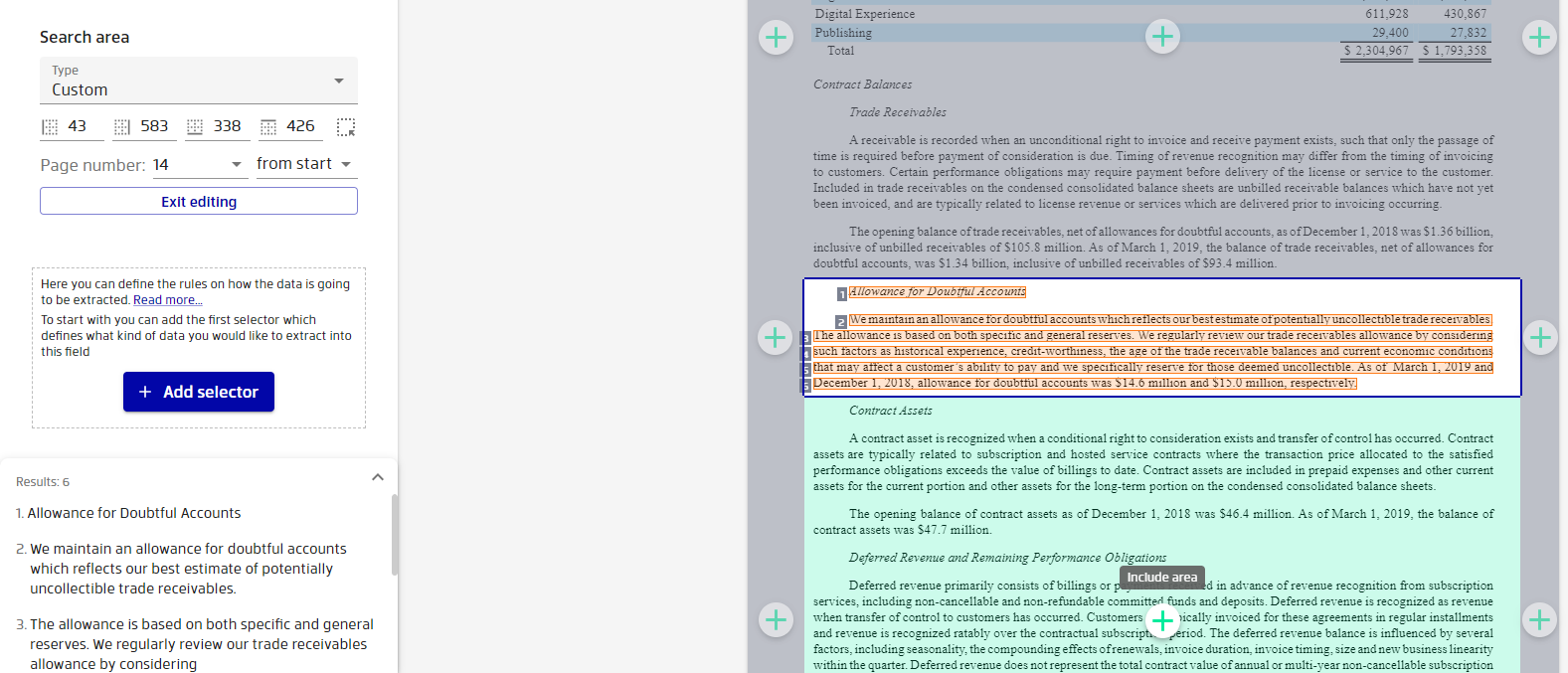
Introducing the Search Area Feature
The new Search area gives greater control over where pdf2Data applies the parsing pipeline in documents. It replaces the previous the Page and Boundary selectors which have now been deprecated. You can restrict the area by specifying a page, page range, or by selecting a specific part of the document. You can then include or exclude parts of the page by clicking on them, as shown below:
You can also watch a tutorial video demonstrating its usage if you prefer.
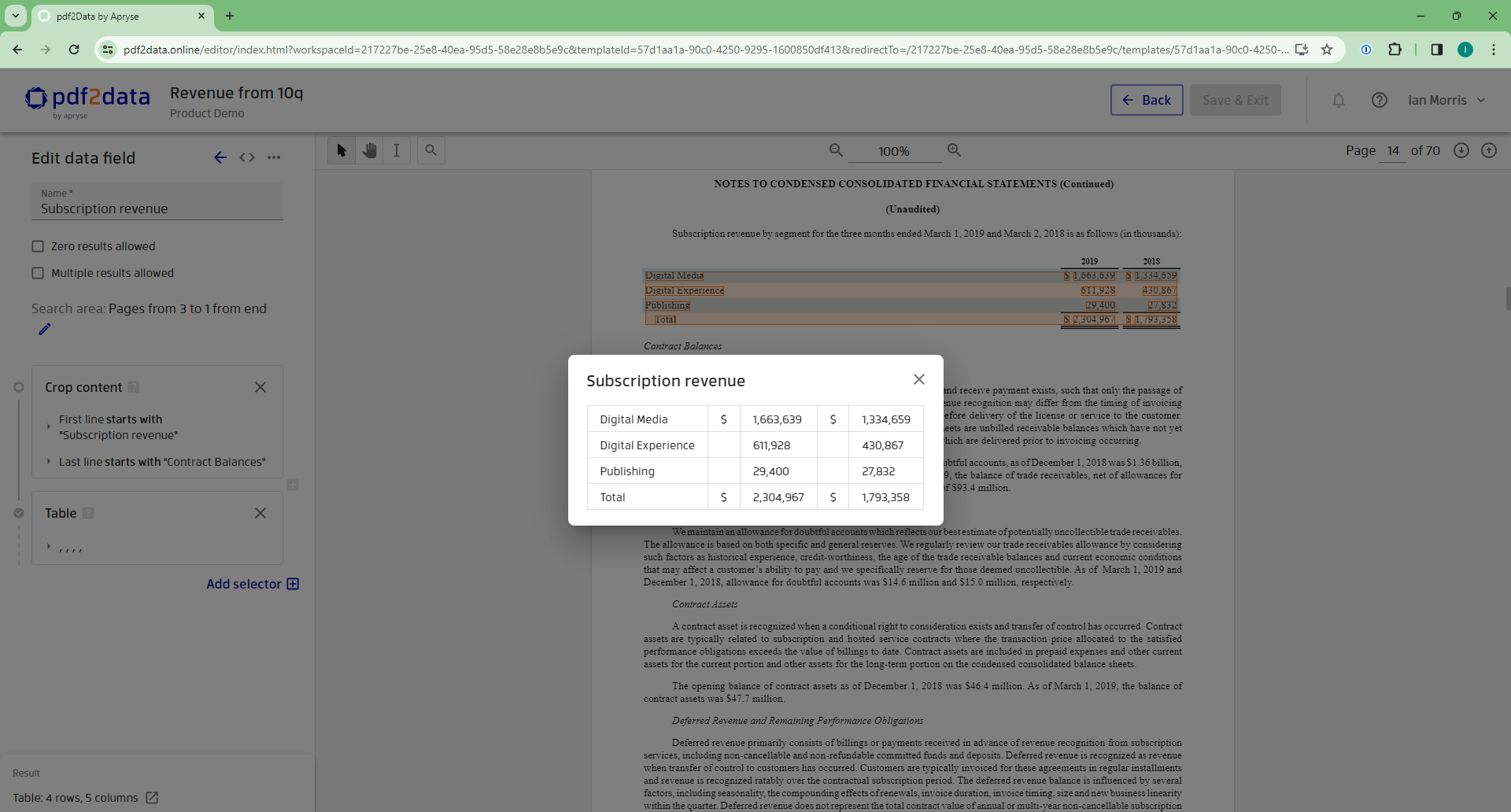
Locate Specific Data with Crop Content
The new Crop content selector allows users to define specific areas of interest in a document based on its content. It's a significant improvement for processing multi-section documents and non-static forms.
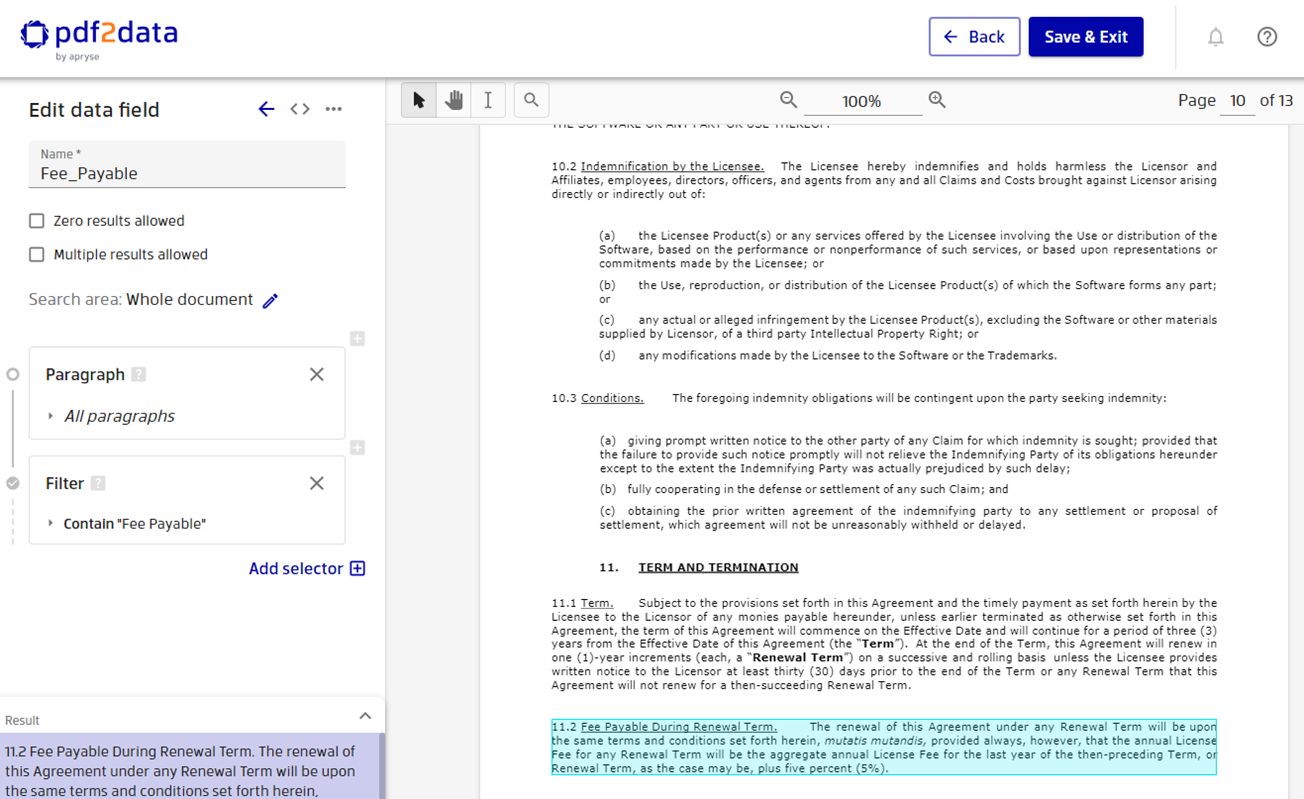
Refine and Restrict Results with the Filter Selector
The Filter selector is a powerful addition that validates and filters extracted values. You can use specific search conditions to exclude unwanted content and ensure only relevant data is captured.
Together, these selectors improve the parsing process, making it more efficient and user-friendly than ever before.
Why Upgrade to pdf2Data 4.4?
If you are looking to enhance your data extraction processes with minimal coding and maximum efficiency, pdf2Data 4.4 is ready for an upgrade today. If you are new to pdf2Data or just want to learn more about how data extraction makes your work easier, faster, and more accurate, reach out today.
What’s Next for pdf2Data?
We have big plans for upcoming releases. Coming soon will be a great new feature where pdf2Data will be able to recognize and extract content from images – not just PDF documents. This will significantly extend pdf2Data’s capabilities and strengthen its position as an essential part of cutting-edge, efficient IDP workflows.
Ready to Dive In?
Download pdf2Data 4.4 today and experience improved data extraction and overall user experience. For a full list of pdf2Data improvements, please see the changelog and other documentation on our website. You can also reach out for a full demonstration if you are new to data extraction solutions.
Alternatively, if you're looking for more code-based solutions you can check out our suite of developer-focused Intelligent Data Extraction capabilities on the Apryse website.
