
Introduction
We are proud to announce the release of iText pdf2Data 3.1.1, the latest version of our template-based data extraction solution. iText pdf2Data intelligently recognizes data inside structured and semi-structured PDF documents and extracts them in a structured format.
iText pdf2Data consists of two main components: as the browser-based pdf2Data Editor which enables creation of extraction templates and the pdf2Data SDK (available for Java, .NET, and as a command-line interface application) that you use to automatically extract data from PDF documents. This data can then be used in customer processes such as business analytics and reporting.
Our main focus of this release is on the SDK side; adding JSON output support to simplify the process of reusing extracted data. We’ve also concentrated on improving the accuracy of our high-level extraction selectors, which help you extract data painlessly without needing any technical knowledge.
What's new
JSON output
First things first, an important innovation in iText pdf2Data 3.1.1 is the introduction of support for JSON format for output data. From now on, both the native Java and .NET SDK libraries and the CLI variant are now able to output extracted data in JSON format as well as XML. This will allow more convenient integration into workflows in microservices and cloud-based solutions, as JSON is the de-facto standard for these applications and so is especially widely used there.
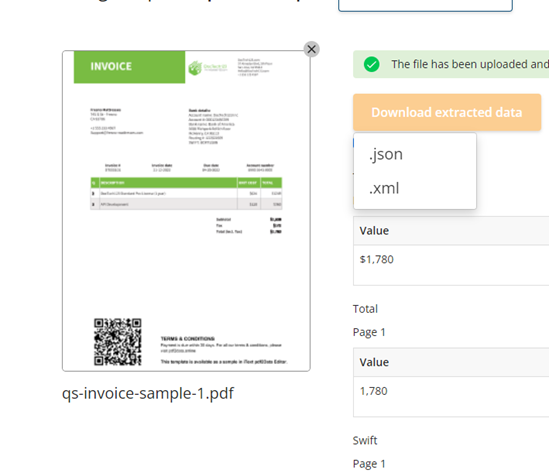
For anyone who prefers to use XML though, don’t worry! This output option is still available and can be used in exactly the same way as before.
Improved data extraction
A key feature of iText pdf2Data is that to ease the process of data extraction, it provides high-level selectors which your less-technical employees can use from the intuitive template editor. The accuracy of these selectors and therefore the extraction algorithms behind them are vitally important for our customers.
In this release, we focused on tweaking two of them in particular: Date and Price. As well as being able to manually configure these selectors to improve extraction, we also improved the validation of extracted values so you will get exactly what you expect in the XML or JSON output. You can now avoid getting outputs such as “32nd of July” from the Date selector or prices in Euros when parsing US invoices.
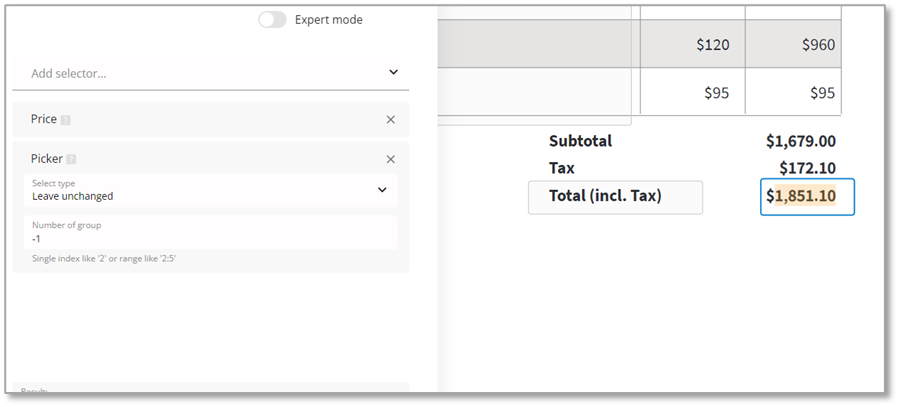
Special mention should be made of the improved table selector since it is a favorite selector of many customers. Indeed, iText pdf2Data features one of the best table extraction algorithms around, and so it is a significant reason our customers use iText pdf2Data. We’re always working to raise the bar for the recognition and extraction of tables in PDF though, and this release is no exception.
Bills of lading, purchase orders, invoices and similar documents often use templates which feature predefined, structured layouts, yet suppliers may need to include important notes for specific products. If there was no provision for this when the template was created the supplier would then need to write the notes directly into the table, and so you might end up with a table being split over multiple pages. In certain cases, this would lead to the table being detected as two separate tables. To prevent this, we’ve modified the table detection heuristics to support variable leading (line-spacing) between table rows.
That’s not all though, as another nice improvement to the table selector is that it can now ignore watermarks. Since watermarks tend to have different styling and don’t respect table structure, they could cause problems for the table detection in previous versions.

Improved user experience
Users can now expect a better experience while creating extraction templates, as we've been making efforts to reduce the learning curve for new users. In addition to the improved high-level selectors, we’ve also revised the messaging in the pdf2Data Editor to provide users with clearer explanations and make it easier to begin data extraction. Of course, we’ll never stop improving our iText pdf2Data documentation regardless of our release schedule, so make sure you keep tabs on our Knowledge Base.
What else?
We’ve fixed a couple of bugs in this release; one for PDFs which contain unsupported color spaces, and an out of memory exception which could occur when grouping lines with the Paragraph selector. As always, you can check our release notes for more details.
If you’re not already an iText pdf2Data customer, you can explore all its features and capabilities with a free 30-day online trial! Alternatively, check out the product page for a detailed overview of how iText pdf2Data works.
You can also visit our Knowledge Base where we have tutorials and a breakdown of all available pdf2Data selectors, including tips on how to use them effectively.
What's next?
Without giving too much away, you can expect some awesome additions and improvements to iText pdf2Data in the future, covering everything from template creation to data extraction, and perhaps even more ?.
See you in the next quarterly release!