Highlights for Data Extraction
- Why you need PDF data extraction
- Different types of PDF documents
- What are structured, semi-structured, and unstructured documents?
- Automating data extraction, intelligent document processing, and more
- The benefits of template-based extraction
PDF and data extraction
Since the introduction of the PDF in 1993 it has become the de facto standard for formal documents and graphically-rich content. It’s not hard to see why; before PDF, there was no way to reliably share a document, including any text formatting, images, etc., regardless of the recipient’s software, hardware, or operating system. It became renowned as the format that could be trusted to ensure a consistent output, whether on screen or in print.
As a general-purpose and reliable digital document format, it is the common way to send and receive commercial documents such as invoices and purchase orders, where the objective is to exchange portable and secure content. In the modern business world, it is becoming increasingly necessary to efficiently capture and extract data contained within such documents, ideally using automated processes.
However, getting access to this data in a usable format can prove challenging, for a number of reasons. Let’s explore the challenges of PDF data extraction, and the solutions.
When is a PDF not a PDF?
Not all PDFs are created equal. If a PDF document such as an invoice has been digitally created by printing to PDF using a software application, its contents will be embedded directly within the document. This can be directly extracted programmatically using a library such as iText Core, or a more user-friendly solution like iText's pdf2Data. You might see PDFs like these referred to as “true” or “native” PDF, “digitally-born”, and so on.
However, to get usable (and reusable) output requires the PDF to have been tagged to identify and provide meta-information about the structural elements of the document. In the example of an invoice, such tags would identify things like the invoice date, supplier address, and so on.
Tagged PDF is one of the primary requirements of the PDF/A standard for long-term archiving, and PDF/UA for universal accessibility. These can be thought of as the “gold standard” of PDF since they make the data and content in in documents much more accessible, with a clear and logical structure. There’s a lot more to these standards than just tags of course, and you can find more information about them and solutions for creating such documents on our dedicated solutions pages linked above.
The problem is that while it is possible to create well-structured PDF documents, you’re unlikely to encounter them when dealing with invoices or purchase orders. A PDF invoice is commonly just a digital version of a paper invoice, and most commercial documents you’ll need to process will be PDFs without any tagged content whatsoever. A notable exception are electronic invoice formats such as ZUGFerd, which uses the PDF/A-3 container capabilities to embed invoice data in a machine-readable XML format with the original invoice.
The worst-case scenario is if the original document was a paper copy that was scanned, so the PDF may simply be a container for a scanned image. In such cases, you would need to rely on OCR to recognize the text and embed it in the PDF, or even resort to reproducing the content before you can think about processing or reusing it. We’ll come back to OCR pre-processing later though.
Structured, semi-structured, and unstructured documents
In general, documents can be categorized into three categories: structured, semi-structured, and unstructured. Understanding the differences between them is key to choosing the right option to automate data extraction from documents.
| Document Types | Format | Examples |
|---|---|---|
| Structured | Fixed and predictable | Government/organization forms, ID cards/passports etc. |
| Semi-structured | Fairly predictable format, though varies from one organization to another | Invoices, purchase orders, bank statements etc. |
| Unstructured | No pre-defined format or structure | Emails, legal contracts, articles, etc. |
It’s important to note that we’re not referring to tags in a PDF structure tree as discussed in the previous section. Instead, it’s purely a description of format and layout of different types of documents.
So, these are the challenges to automated PDF data extraction. What about the solutions?
Automating data extraction
The traditional way to extract data from business documents would require someone to transfer data from documents manually. Of course, this takes a lot of time and resources, with the risk of input errors or security issues to consider. What if you could automate this process in a reliable and secure way?
In recent years business process automation has become increasingly important. Intelligent Document Processing (IDP) is a set of technologies to process documents intelligently, helping businesses to extract and store data as simply and efficiently as possible.
A number of IDP solutions use artificial intelligence (AI) technologies such as machine learning (ML) and natural language processing (NLP) to classify and extract data. Such solutions can produce great results, particularly for processing unstructured documents.
AI isn’t a magic bullet though - it needs extensive training to produce accurate results and human supervision. On top of that, any changes to document format will require retraining of the detection model.
For more structured documents then, a more efficient method is to take advantage of the predictability of their layouts.
Template-based extraction
While AI and related technologies can be particularly useful for handling less structured documents such as emails, structured (official forms, passports, ID cards etc.) and semi-structured documents (invoices, bank statements etc.) can instead be handled more efficiently using a more rules-based approach.
If we take the example of an invoice document, addresses, purchase order numbers and similar document elements tend to be located in one place, and only the content such as item descriptions, quantities and cost of items change from invoice to invoice. By using an example invoice as a template, it is possible to define areas of the document where the data you want to capture is located and categorize it.
This is the approach pdf2Data takes for data extraction. iText's pdf2Data is a solution which offers an easy way to extract data from such PDF documents by defining areas and rules in a template which correspond to the content you want to extract. The template can then be visually validated with other documents to confirm data is recognized correctly.
All subsequent documents matching that template can then be automatically parsed without any user intervention. You only need one example document to enable reliable automated data extraction.
Unlike AI-based alternatives, you don’t need hundreds of samples and intensive supervision to train the recognition process. The content recognition is controlled by the template you configure, meaning you can begin extracting data straight away.
AI recognition has other disadvantages too. Any changes to the required output (such as adding a new field) will require models to be retrained, and multiple language support is minimal at best. Documents using the same layout but containing content in different languages can give wildly inconsistent results.
iText's pdf2Data on the other hand suffers from none of these drawbacks. Making modifications to templates is quick and easy, and it offers excellent language support. It also provides powerful table recognition functionality, which is one of the primary shortcomings of other data extraction solutions.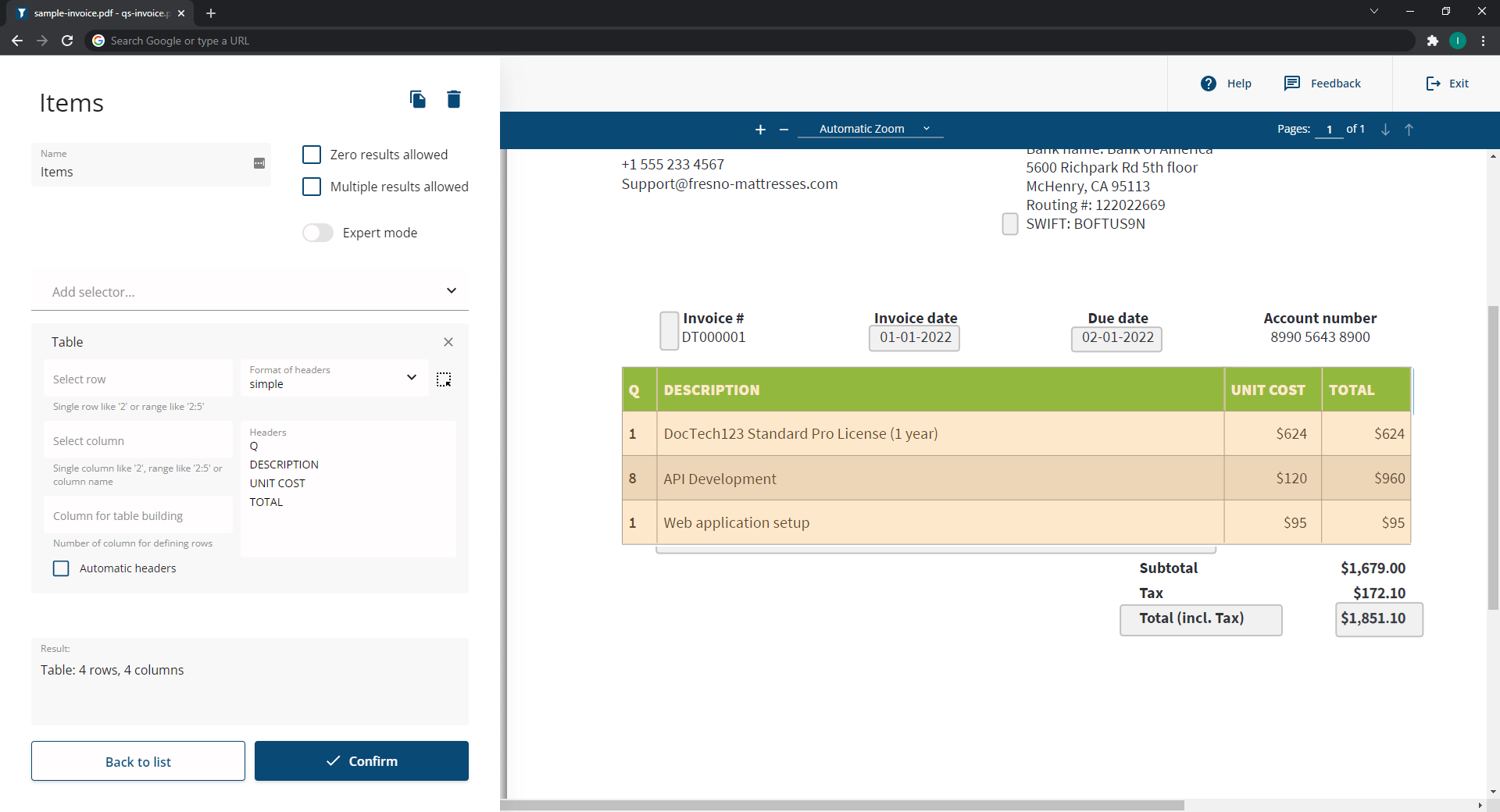
What about OCR?
iText's pdf2Data contains all you need to automate a PDF data extraction workflow, yet what if you need to digitalize paper documents, or process PDF documents which are just scanned images? That’s where an OCR solution is required.
We have the pdfOCR add-on for the iText Core PDF library which turns scanned documents and images into PDF (or PDF/A-3u if you need long-term archiving compliance) ready to be processed by pdf2Data. Depending on your requirements, your workflows may also benefit from using iText Core for additional pre- or post-processing tasks, or any of the other add-ons available in the iText Suite.
How pdf2Data works
By using the intuitive browser-based pdf2Data Editor, it’s easy to create a template for data extraction. Simply create a template PDF based on a sample document, by defining data field selectors for areas of interest. Selectors are configurable rules to detect different types of content for extraction, and many can be combined to fine-tune detection parameters.
There are approximately two dozen selectors to choose from which enable pdf2Data to intelligently recognize and extract text, and other content such as images or barcodes. The selectors can be configured to detect:
- page range and the position on the page
- specific font styles, font color, and text patterns
- fixed keywords next to the data
- automatic recognition of table structures
Similar to our document generation solution iText DITO, pdf2Data allows anyone to leverage iText's powerful PDF capabilities, not just developers. By intelligently extracting data from documents in a smart and structured way, the data can easily be repurposed for analysis, reports, or whatever you want.
Developers are only needed to deploy the pdf2Data Editor and integrate the pdf2Data SDK into your document workflow. From then on, you can configure a template, verify the data, and set pdf2Data to work.
Once the pdf2Data components have been deployed and integrated into an automated document workflow, it's simple to create or refine document templates to recognize and automatically extract data, which can then be easily reused by whoever needs it.