
Following our recent article comparing the iText 5 Chunk and iText 8 Text classes, this time we’re going to look at another significant improvement iText 8 offers over iText 5 and earlier versions: creating PDFs from HTML templates.
More specifically, this article will focus on using HTML to create PDF/A documents which are suitable for long-term archiving purposes. We’ll demonstrate how the pdfHTML add-on enables you to reuse the inherent structure of HTML to easily create archive-ready PDF/A compliant documents, and how modern iText releases make it easier than ever!
Why HTML Templating Makes Sense for PDF/A Generation
The iText Core library provides high-level APIs which make PDF/A creation easier than many competing libraries. However, since the PDF/A standard is designed for the long-term preservation of electronic documents, achieving PDF/A conformance does require extra work compared to regular PDF.
Rather than creating documents from scratch, using HTML as a source makes a lot of sense since you can reuse the styling and inherent structure of HTML to create the structural information and semantic tagging required for the PDF/A conformance level you’re targeting. This can save significant time and effort in the design and layout of documents, and avoids the need to manually add tags to describe the document’s logical structure and content.
There are currently four versions of the PDF/A standard, each with different conformance levels. Which version and flavor of conformance level you need depends on your specific requirements, with later versions supporting newer PDF features. For a detailed rundown of the various PDF/A standards you can refer to this article on the Apryse website; we’ll just focus on the basics here.
This article’s aim is to show the ease of converting from HTML to a PDF/A document with iText 8, compared to iText 5. For the purposes of this comparison, we’re targeting PDF/A-3 with level B conformance. Why specifically PDF/A-3B?
- While the PDF/A-1 and PDF/A-2 standards are still valid choices for archiving documents, PDF/A-3 is more flexible, supporting features like transparency, layers, and attachments of any file type.
- The PDF/A-3 standard is supported by both iText 5 and iText 8, allowing a like-for-like comparison between the two.
- Level B conformance is the easiest level to achieve, which allows us to keep both examples as short as possible.
Don’t worry, we’ll also cover how you can achieve higher conformance levels and target other PDF/A versions later in the article.
What We’re Aiming For
The HTML we’re using is fairly simple, at least to begin with. There is a heading followed by an image, and then two paragraphs of text. After this though, we get a little more advanced with two styled <div> elements, and an assortment of HTML form elements.
<html>
<head>
<link rel="stylesheet" href="styles.css">
</link>
<title>Test</title>
</head>
<body>
<h1>Hello world!</h1>
<img src="images/bee.jpg" alt="Bee on flower" id="img1"></img>
<br></br>
<p id="example3">Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin condimentum tempus turpis, efficitur
malesuada ligula placerat nec. Pellentesque ac scelerisque ligula, in semper dui. Praesent eleifend vel magna
in feugiat. Interdum et malesuada fames ac ante ipsum primis in faucibus. Quisque eu tellus volutpat, fermentum
nunc in, auctor lacus.</p>
<br></br>
<p id="example4">Sed venenatis justo a felis tempor viverra. Nullam et molestie leo. Etiam at enim commodo,
ullamcorper ante quis, interdum odio. Ut in metus vel nulla pellentesque viverra at non libero. Mauris
suscipit posuere sem, ut fringilla eros hendrerit tempus. Donec id sagittis sem. Etiam at molestie quam.</p>
<div id="example1">
Here we have background with background-clip property
</div>
<form>
<p>Gradient Test</p>
</form>
<div id="example2">
<p>Opacity Test</p>
</div>
<!--example of acroforms handling-->
<input type="checkbox" name="" value="some text" lang="ru"></input>
<input type="text" name="" value="some text" lang="by"></input>
<input type="radio" name="radio1" value="some text" lang="fr"></input>
<input type="button" name="" value="some text" lang="en"></input>
<textarea lang="uk">Some text</textarea>
</body>
</html>Speaking of styling, here is the CSS:
body{
font-family: noto sans;
height: 100vh;
}
img {
filter: blur(5px);
}
#example1 {
background-image: linear-gradient(#e66465, #9198e5);;
background-clip: border-box;
background-repeat: no-repeat;
padding: 20px;
border: 10px dashed;
}
#example2 {
width: 250px;
height: 250px;
background-color: blue;
opacity: 0.3;
}
#example3 {
width:20%;
}
#example4 {
width:50em;
}
#img1 {
width:200px;
}As you can see, we have specified the Noto Sans font and set variable widths for two paragraphs - one of 20%, and the other set to 50em. We’re also using the background and gradient CSS properties for some text, and a blue box with an opacity of 0.3.
Put together, it renders like this in a modern browser:

We’re aiming to get as close as possible to this in our PDF/A-3B document, with the minimum of effort.
Creating PDF/A from HTML with iText 5
First, let's look at how you would use iText 5 to create a PDF/A conformant document from HTML. The process consists of a standard HTML conversion with the XMLWorker class, with a few extra steps:
String htmlPath = SRC + "MixedContent5.html";
String cssPath = SRC + "styles.css";
String fontPath = SRC + "fonts";
String colorspacePath = SRC + "sRGB Color Space Profile.icm";
OutputStream file = new FileOutputStream(SRC + "test.pdf");
Document document = new Document(PageSize.A4);
PdfWriter writer = PdfAWriter.getInstance(document, file, PdfAConformanceLevel.PDF_A_3B);
document.open();
document.addTitle("Test");
// Creating XMP metadata is a PDF/A requirement
writer.createXmpMetadata();
document.open();
// Setting output intent
ICC_Profile icc = ICC_Profile.getInstance(new FileInputStream(colorspacePath));
writer.setOutputIntents("Custom", "", "http://www.color.org", "sRGB IEC61966-2.1", icc);
// Adding CSS
CSSResolver cssResolver = new StyleAttrCSSResolver();
CssFile cssFile = XMLWorkerHelper.getCSS(new FileInputStream(cssPath));
cssResolver.addCss(cssFile);
HtmlPipelineContext htmlContext = new HtmlPipelineContext(
new CssAppliersImpl(new XMLWorkerFontProvider(fontPath)))
.setTagFactory(Tags.getHtmlTagProcessorFactory())
.setImageProvider(new AbstractImageProvider() {
public String getImageRootPath() {
return SRC;
}
})
.setAcceptUnknown(true).autoBookmark(true).setTagFactory(Tags.getHtmlTagProcessorFactory());
HtmlPipeline html = new HtmlPipeline(htmlContext, new PdfWriterPipeline(document, writer));
Pipeline<?> css = new CssResolverPipeline(cssResolver, html);
XMLWorker worker = new XMLWorker(css, true);
XMLParser xmlParser = new XMLParser(true, worker, Charset.forName("UTF-8"));
xmlParser.parse(new FileInputStream(htmlPath), Charset.forName("UTF-8"));
document.close();
}
public static class MyFontProvider extends FontFactoryImp {
private BaseFont font;
public MyFontProvider() throws DocumentException, IOException {
font = BaseFont.createFont("C:\\Development\\test\\NotoSans-Regular.ttf", BaseFont.WINANSI, true);
defaultEmbedding = true;
}
@Override
public Font getFont(String fontname, String encoding, boolean embedded,
float size, int style, BaseColor color, boolean cached) {
//return super.getFont(fontname, encoding, embedded, size, style, color, cached);
return new Font(font, size, style, color);
}Let’s break down what this code is doing.
- First, we define the paths to our HTML and CSS files, and the font file we’ll use to create the PDF. In addition, we provide iText with an ICC color profile file to use since this is one of the PDF/A requirements. More detail on that later.
- The next step is to create an output stream for the PDF file, and then we create a new
Documentinstance and set an A4 page size. We also create aPdfAWriterinstance, which is a subclass ofPdfWriter, and set it to create a document meeting the PDF/A-3B conformance level. - We open the created document and give it a title, which is a requirement of PDF/A conformance.
- We then create the XMP metadata, which is another of the PDF/A requirements.
- We load the ICC color profile from the file and set it as the output intent to define the color space for the document.
- We set up a CSS resolver to apply the CSS styles, along with an HTML pipeline to handle the HTML content, and an image provider to handle the embedded image.
- A custom
MyFontProviderclass is created to embed a specific font (NotoSans-Regular.ttf) into the PDF. - A series of pipelines then parses and converts the HTML, and the content is added to the document.
- The document is closed, finalizing the PDF.
As you might notice, we’re having to do quite a lot of low-level operations on iText 5’s classes and methods, for example PdfAWriter and Document, in order to meet the PDF/A requirements. We also need to fine-tune a bunch of classes to correctly process our HTML/CSS, along with image embedding.
On top of all that, we must manually create the required XMP metadata, and then create our own font provider to supply the fonts which will be embedded into the document.
Verifying Conversion Results and PDF/A Conformance
If we just wanted to ensure our file meets the PDF/A-3B conformance level, we could use the industry-standard veraPDF tool. However, we also want to render the document to see how closely the iText 5 conversion got to the source. To do this, we’ll use Xodo PDF Studio, a brand-new member of the Apryse software family.
PDF Studio is a great, easy-to-use Acrobat-alternative for Windows, macOS, and Linux, and has a ton of powerful features which you can read about in this blog post if you’re interested.
Aside from being an excellent PDF editor and viewer, one small, yet useful feature is PDF Studio identifies when a document is tagged as PDF/A, and clearly displays the stated conformance level:
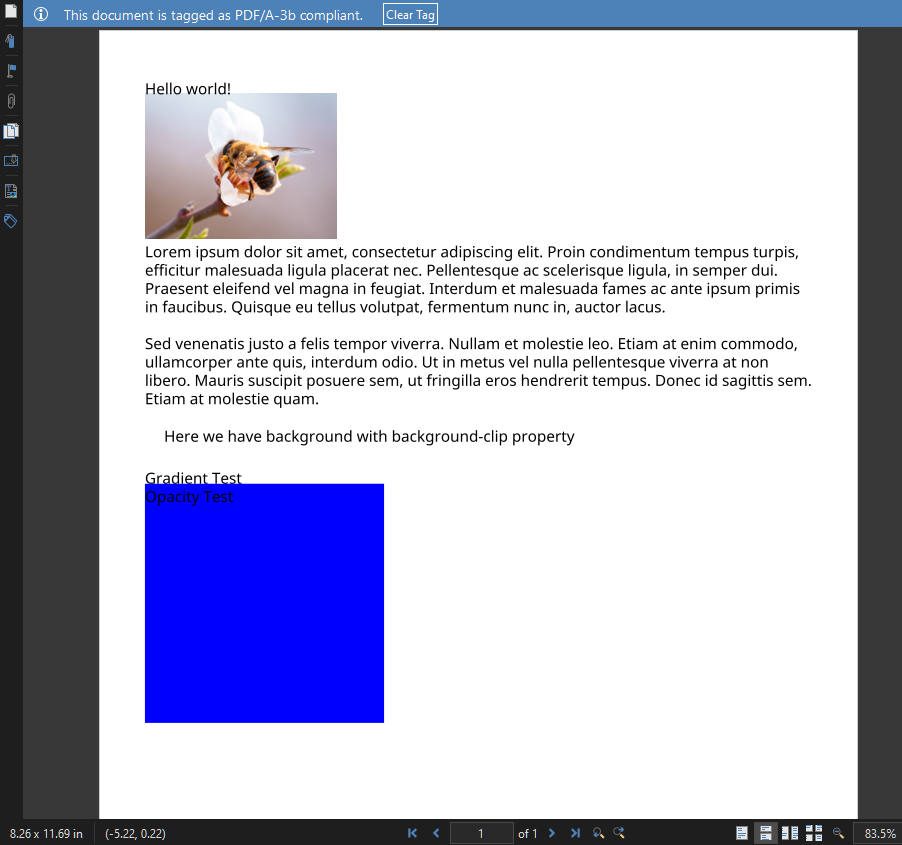
So, how did iText 5 perform? We certainly have a PDF/A-3B conformant document, the embedded image is present, and the specified font was used and embedded correctly.
However, the text content did not fare as well, with paragraph width settings and even the H1 heading being ignored. Our CSS for the background gradient and opacity properties did not work at all, with the blue box rendered as 100% blue. Worst of all though, our form elements are completely missing.
Given enough time and effort, a talented developer might find fixes and workarounds for at least some of these issues. For example, iText 5 does not add styling to headings by default, so this must be added manually, e.g.:
h1 { font-size: 2em; font-weight: bold; margin: 0.67em 0; }For the rest though, we’re pretty much out of luck. The XMLWorker in iText 5 is completely oblivious to more modern HTML and CSS, since active development ended in 2016. That’s because something new, and much better came along…
PDF/A Creation from HTML with iText 8
In contrast to iText 5, HTML conversion in iText versions 7 and above uses the pdfHTML (Java/.NET) add-on which offers significantly enhanced HTML and CSS conversion capabilities.
The code below targets a recent version of pdfHTML for iText Core version 8, enabling us to take full advantage of the latest developments in HTML conversion and PDF/A document creation:
String htmlSource = SRC + "MixedContent.html";
InputStream inputStream = new FileInputStream(SRC + "sRGB Color Space Profile.icm");
ConverterProperties converterProperties = new ConverterProperties();
converterProperties.setBaseUri(SRC);
converterProperties.setCreateAcroForm(true);
// Set the desired PDF/A level the output pdf file should comply to
converterProperties.setPdfAConformanceLevel(PdfAConformanceLevel.PDF_A_3B);
// Set output intent for the output pdf file
converterProperties.setDocumentOutputIntent(
new PdfOutputIntent("Custom", "", "http://www.color.org", "sRGB IEC61966-2.1",
inputStream));
HtmlConverter.convertToPdf(new File(htmlSource), new File(pdfDest), converterProperties);You’ll immediately notice our code is much shorter and less complex than our first example. Let’s take a closer look to understand why.
First, pdfHTML supports inline CSS, thus avoiding the need to specify and process a separate CSS file. In addition, we no longer need to mess around with custom font providers and low-level manipulation of classes. All we need to do is simply pass a ConverterProperties (Java/.NET) configuration object into the HtmlConverter (Java/.NET), and the rest will be handled automatically for you.
Much of the magic happens in the ConverterProperties class which is highly-customizable - as you can see from the API docs linked above. In our example, we specify:
setBaseUri(SRC): This sets the base URI that will be used for resolving relative URLs.setCreateAcroForm(true): This enables the creation of AcroForms (interactive PDF forms) from HTML form elements. Unlike iText 5, iText 8 can create interactive form fields from HTML forms, and automatically takes care of their PDF/A conformance for you.
In addition, we specify a couple of PDF/A-specific properties:
setPdfAConformanceLevel(PdfAConformanceLevel.PDF_A_3B): This sets the PDF/A conformance level for the resulting PDF to PDF/A-3B.setDocumentOutputIntent(...): This sets the output intent for the PDF, which is a description of the destination device for color reproduction.
This neatly demonstrates a recent improvement introduced in pdfHTML 5.0.3. We added specific methods to ConverterProperties to streamline the underlying object instantiation processes for conformance levels and output intent. Previously, developers would need to set these objects up manually.
As mentioned earlier, PDF/A requires that all content is specified using device-independent colors and associated with an ICC profile to be used on the target output device. Keep in mind that PDF/A (at least, for PDF/A-3 and earlier) allows only a single ICC profile to be associated with a PDF.
This means in most cases; you can only use one type of device-dependent color space: either RGB or CMYK (this includes the color space for images). Since default HTML/CSS colors are RGB based, we naturally choose the RGB color profile.
Behind the scenes, iText Core automatically handles the rest of the PDF/A requirements. For example:
- Fonts used in the document will be embedded by default, or if you define fonts in CSS by using the
@font-faceat-rule - something you had to manually take care of in iText 5. - Alternatively, if you provide the required fonts via the
FontProvider(Java/.NET), iText 8 will ensure that you’ve configured the font embedding correctly. If any issues are detected, aPdfAConformanceExceptionwill be thrown with an explanatory message to help you track down the problem.
Verifying the pdfHTML Results
Once again, let's check our results in Xodo PDF Studio to see how we did:
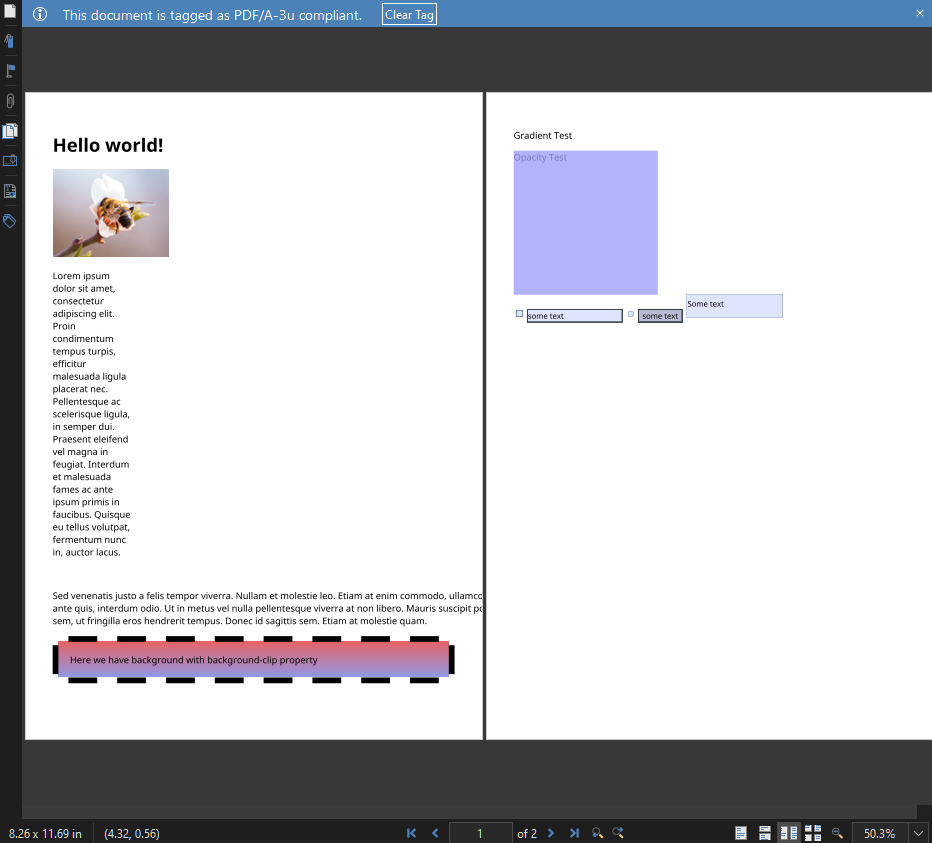
As you can see, we have a much closer match for the original HTML this time round. Most importantly, those elements using the advanced CSS background properties have been translated exactly as rendered in the browser, and our HTML forms are represented by the equivalent PDF form controls.
If you want to reproduce our results or experiment further, you can find full Java and C# versions of the code snippet in the pdfHTML sample repository on GitHub, along with the required resources.
Targeting Other PDF/A Conformance Levels
In many cases, level B conformance is sufficient for the digital preservation of documents. It guarantees the visual appearance and future reproducibility of documents, and is well-suited for use cases such as archiving emails for compliance or record-keeping purposes.
However, if you want the content to be searchable, accessible, and reusable, or ensure reliable text extraction, you should aim for a higher conformance level. For the PDF/A-3 standard, there are two additional levels: Level U (for Unicode) requires Unicode mapping, while Level A (for “accessible”) requires embedded structure information as well as Unicode text.
In Chapter 4 of our Converting HTML to PDF with pdfHTML tutorial, we have a dedicated section on generating PDF/A documents. As noted, to achieve Level A conformance requires adding an extra line: pdf.setTagged() (Java/.NET) which instructs iText to create a Tagged PDF. This translates the structural and semantic information in your HTML into a hierarchical PDF structure tree. This means Headings, Paragraphs, Lists, and Tables etc. can be logically organized and labeled with the semantic tagging required for achieving conformance level A.
Chapter 4 also covers creating a PDF/A-3 document containing an XML attachment using the addFileAttachment() (Java/.NET) method, This is a common use case for e-invoicing, since it provides both a human-readable invoice as well as a machine-readable version in XML format, in an archive-ready container format.
As for PDF/A-4, support was added with the release of iText Core 8.0.2. You can refer to this page for more details on the differences between PDF/A-4 and previous versions, along with code examples for creating PDF/A-4 documents.
HTML to PDF with iText - Then and Now
As we’ve seen, iText 5 used the XMLWorker class for working with HTML - which itself was a development of the HTMLWorker in earlier versions of iText.
In contrast, the release of iText version 7 introduced a new and more logical modular structure for iText Core which has been carried forward into iText version 8. Instead of the monolithic nature of previous versions, this enables developers to pick and choose which modules they want to load at startup, and only use the functionality you need.
It also allowed us to easily extend the functionality of the core library with optional add-on modules. One of the first add-ons to be released was pdfHTML, a major improvement over the options available in previous iText versions. Here’s a quick comparison:
- HTMLWorker for iText versions 1 and 2 was designed to parse small, simple HTML snippets and (very limited) CSS.
- XMLWorker for iText/iTextSharp version 5 was a much improved and extensible solution; though CSS support was patchy, and it expected XHTML rather than HTML.
- pdfHTML for Text version 7 (and subsequent releases) was written to take full advantage of the new Layout API and Renderer framework introduced with iText 7, and be fully customizable and extendable. It intelligently parses and processes your HTML/XML and CSS content, turning it into the equivalent iText objects and styles for the PDF document.
Like iText itself, pdfHTML has come a long way since its initial releases, with expanded support for HTML5 and newer CSS tags and attributes. Additions from previous releases include vertical-align, device-cmyk, object-fit, overflow-wrap and word-break, among many others.
More notably, recent additions added support for the flexbox and multi-column layout modules, with grid layout support due to appear in the upcoming pdfHTML 5.0.5 release.
Not only that, close integration with the iText Core library allows pdfHTML to take advantage of newer Core features, such as support for SVG, and the brand-new PDF/UA-2 standard for universal accessibility.
In addition, recent iText 8 releases have much improved support for creating PDF/A documents: whether you’re converting from HTML templates or creating from scratch using iText Core’s high-level APIs. This includes support for the latest PDF/A-4 standard based on the PDF 2.0 specification, whereas iText 5 only supports PDF/A creation up to the PDF 1.7-based PDF/A-3 standard.
Extending pdfHTML with Custom Functionality
As mentioned earlier, there’s a ton of customization available in the pdfHTML API, with only a fraction of its out-of-the-box functionality being used for this article.
However, the possibilities do not end there. There are two plugin mechanisms in pdfHTML which allow you to extend its functionality to execute custom behavior for HTML/CSS conversions, which we’ll briefly touch on below.
TagWorkerFactory
You can override the DefaultTagWorkerFactory (Java/.NET) to change the default HTML tag handling behavior. There are various reasons why you might want to do this, such as handling tags in a custom way, or to implement your own custom tag definitions.
For example, you could create a custom ITagWorker (Java/.NET) implementation to dynamically generate and add QR codes from a <qr> tag in your HTML. Your TagWorker can then use the iText Core APIs to generate the QR code and add it to your document, without requiring a separate image.
CssApplierFactory
By default, pdfHTML only executes CSS logic on standard HTML tags. So, if you have a defined a custom tag as in the previous example, you’ll need to write an ICssApplier (Java/.NET) to apply CSS to it, and extend the DefaultTagWorkerFactory to register it.
Alternatively, if you want to change how a standard HTML tag reacts to a CSS property, you can extend the ICssApplier for that tag and write your own custom logic.
You can learn more in Chapter 5 of the pdfHTML tutorial, where creating custom tag workers and CSS appliers is more comprehensively covered, along with handy Java and C# code examples.
Conclusion
To wrap up this second article in our series comparing iText 8 and iText 5 ways of doing things, we’ve demonstrated yet more major advances in iText 8’s PDF capabilities. Whether you need PDF/A, PDF/UA, or just standard PDF, pdfHTML makes a great partner for iText Core and is a vast improvement for HTML conversion tasks, producing more accurate results with much less coding required.
Just like iText Core, pdfHTML is completely open source and free to use under the AGPLv3 terms (or a commercial license if you prefer). Not to mention, pdfHTML can automatically take advantage of other iText Suite add-ons such as pdfCalligraph, which allows the conversion of text written in global languages and complex writing systems, such as Arabic, Thai, Hebrew, and many more.
If you want to try out the entire iText Suite, our free 30-day trial includes iText Core and all our open and closed source add-ons. The trial is covered by the terms of our commercial license, which releases you from the AGPLv3 conditions and keeps your intellectual property safe.



