
Introduction
In this article, we’re going to focus on iText Core’s high-level text and content functionality by comparing the Chunk class from iText 5 and the Text class we introduced in iText 7. At first glance, these classes do pretty much the same thing, but as we’ll see, the Text class in iText Core versions 7 and 8 is much more flexible and extensible.
Since the very first public release of the iText PDF library way back in 2000, it has developed into a hugely popular and feature-rich PDF SDK. Now we’re part of the Apryse family, we’re continuing to develop and expand on its capabilities, such as the release of iText Core version 8 earlier this year. One of the key advantages iText offers to developers compared to other PDF libraries is its high-level API, which simplifies the process of creating and manipulating PDFs by abstracting away many of the low-level details and complexities of PDF development.
With the release of iText 7 in 2016 however, we took the opportunity to rewrite the API to provide better abstractions and encapsulation of common tasks, making it more intuitive and developer-friendly for PDF generation and manipulation. This means that there are some major differences in iText Core’s key high-level API functions compared to iText 5 and earlier versions.
Understanding Layout in iText
Before we go any further, it’s important to understand that one of the fundamental differences of iText 7 and later versions is that the core library was split into multiple, separate modules. These modules handle specific functionality, such as text manipulation, layout, signing, and more. This modularity allows developers to include only the modules they need, reducing the overall size of the library in their projects and improving maintainability.
Since the PDF format only allows for low-level operations like "draw a character at a given position" or "draw a line from (x1,y1) to (x2, y2)", the layout module contains the logic for iText’s rendering engine that relieves the pain of calculating and positioning elements, and constructing the required complex drawing operations in PDF syntax.
There’s a lot more to the layout module than we need to go into here, so we recommend reading the documentation for the layout module (Java/.NET) to learn more about the rendering engine, and concepts such as property containers, and layout objects. In short though, it is responsible for transforming abstract elements (such as Paragraph, Table, and List) and then arranging and positioning them on the page.
So, What’s the Difference Between Chunk and Text?
The iText 5 API documentation describes a Chunk as the following:
This is the smallest significant part of text that can be added to a document.
Most elements can be divided in one or more Chunks. A chunk is a String with a certain Font. All other layout parameters should be defined in the object to which this chunk of text is added.
In comparison, the Text class in iText 8 (and 7) is defined as:
A Text is a piece of text of any length. As a leaf element, it is the smallest piece of content that may bear specific layout attributes.
Hold On, What’s a Leaf Element?
The term "leaf element" refers to a specific type of element in the document object model (DOM) hierarchy. Since the PDF format does not inherently represent content in such a way, this is one of the areas where iText really shines by providing abstractions for the complex PDF syntax required to create and manipulate PDFs. The DOM in iText represents the logical structure of a PDF document as a tree-like structure, where elements are organized in a hierarchical manner.
In this context, a "leaf element" is an element that does not have any child elements. It is a standalone element without any further nesting or subdivision within the document structure. Leaf elements typically represent basic content elements like text, images, or graphical shapes that are not meant to contain other elements.
For example, in the context of a Paragraph element, the text content within the paragraph (e.g., "Hello, World!") would be considered a leaf element because it is the smallest, indivisible content unit within the paragraph. Similarly, an Image element that represents a single image without any nested elements would also be a leaf element.
Leaf elements are essential building blocks of a PDF document's content. They represent the actual data that needs to be rendered on the page, as opposed to container elements (non-leaf elements) that provide structure and organization to the content.
How to Use Chunk in iText 5
The Chunk class in iText 5 was designed for creating individual, stylized text units within a PDF document. It provides various formatting options like font, color, underline, hyphenation, and more. Developers are able to customize the appearance of text by chaining methods onto the Chunk instance, allowing for detailed control over each chunk's styling. However, chaining numerous methods can lead to overly verbose code, particularly in complex documents.
Below is a simple Java example showing how you would use the Chunk class in iText 5. It defines a series of different chunks with custom fonts and formatting:
import com.itextpdf.text.*;
import com.itextpdf.text.Font.FontFamily;
import com.itextpdf.text.pdf.PdfContentByte;
import com.itextpdf.text.pdf.PdfWriter;
import java.io.FileOutputStream;
import java.io.IOException;
public class ChunkExample {
/**
* The resulting PDF file.
*/
public static final String RESULT = "./src/main/resources/resultChunk.pdf";
public static void main(String[] args) throws IOException, DocumentException {
new ChunkExample().createPdf(RESULT);
}
/**
* Creates a PDF document.
*
* @param filename the path to the new PDF document
* @throws DocumentException
* @throws IOException
*/
public void createPdf(String filename) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream(filename)).setInitialLeading(16);
document.open();
Font font = new Font(FontFamily.HELVETICA, 6, Font.BOLD, BaseColor.WHITE);
document.add(new Chunk("Default text chunk \n\n"));
Chunk chunk = new Chunk("Text chunk with some properties", font);
chunk.setBackground(new BaseColor(8, 73, 117), 1f, 0.5f, 1f, 1.5f)
.setTextRise(6)
.setUnderline(new BaseColor(249, 157, 37), 2, 0, 3, 0, PdfContentByte.LINE_CAP_BUTT)
.setWordSpacing(10)
.setHorizontalScaling(2)
.append(" and appended text");
document.add(chunk);
document.add(Chunk.createWhitespace("Create whitespace"));
document.add(Chunk.NEWLINE);
document.close();
}
}
This will produce a PDF that looks like this:

You’ll notice there are some issues with the text with the blue background since parts of it (“ed text”) are effectively invisible. That’s not too important right now though, it’s just a demonstration of its functionality.
How to Use the New Text Class
In comparison, the Text class revolutionizes text manipulation by providing a more streamlined and flexible approach. It allows developers to create styled text with properties like Chunk, but with a cleaner syntax and improved readability. Instead of chaining methods on the same instance, developers can create a Text object and apply properties individually, resulting in simpler and more maintainable code.
The following Java example demonstrates some of the capabilities of the Text class in iText 7/8:
import com.itextpdf.io.font.constants.StandardFonts;
import com.itextpdf.kernel.colors.ColorConstants;
import com.itextpdf.kernel.colors.DeviceRgb;
import com.itextpdf.kernel.font.PdfFont;
import com.itextpdf.kernel.font.PdfFontFactory;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.kernel.pdf.canvas.PdfCanvasConstants;
import com.itextpdf.layout.Document;
import com.itextpdf.layout.borders.SolidBorder;
import com.itextpdf.layout.element.Paragraph;
import com.itextpdf.layout.element.Text;
import com.itextpdf.text.pdf.PdfContentByte;
import java.io.IOException;
public class TextExample {
/**
* The resulting PDF file.
*/
public static final String RESULT = "./src/main/resources/resultText.pdf";
public static void main(String[] args) throws IOException {
new TextExample().createPdf(RESULT);
}
/**
* Creates a PDF document.
*
* @param filename the path to the new PDF document
*/
public void createPdf(String filename) throws IOException {
Document document = new Document(new PdfDocument(new PdfWriter(filename)));
PdfFont font = PdfFontFactory.createFont(StandardFonts.HELVETICA_BOLD);
Paragraph paragraph = new Paragraph();
paragraph.add(new Text("Default text chunk \n\n"));
Text chunk = new Text("Text chunk with some properties").setFont(font).setFontSize(6).setFontColor(ColorConstants.WHITE);
chunk.setBackgroundColor(new DeviceRgb(8, 73, 117), 1f, 0.5f, 1f, 1.5f)
.setTextRise(6)
.setUnderline(new DeviceRgb(249, 157, 37), 2, 0, 3, 0, PdfContentByte.LINE_CAP_BUTT)
.setWordSpacing(10)
.setHorizontalScaling(2)
.setText(chunk.getText() + " and appended text");
paragraph.add(chunk);
document.add(paragraph);
Paragraph anotherParagraph = new Paragraph();
Text text = new Text("More customized text example").setFont(font).setFontSize(20).setFontColor(ColorConstants.WHITE)
.setBorder(new SolidBorder(new DeviceRgb(8, 73, 117), 3))
.setLineThrough()
.setTextRenderingMode(PdfCanvasConstants.TextRenderingMode.FILL_STROKE)
.setStrokeColor(new DeviceRgb(249, 157, 37));
anotherParagraph.add(text);
document.add(anotherParagraph);
document.close();
}
}
This will produce a PDF that looks like this:

The result is pretty similar to the first, although you’ll notice there is no “invisible” text this time; the blue background is rendered correctly for all the text. At the code level though, the main difference is the styling such as the font and text color are set by using chaining methods on the Text object directly, making the code more streamlined compared to our first example.
However, the second example also showcases how iText Core versions 7 and 8 enable additional text styling and configuration, like base direction, border, italic, bold, line-through, and stroke color settings. For the second paragraph, we use the setNextRenderer method which allows you to create a custom renderer for the Text element and define how it should be drawn on the PDF document. With this method, you can customize the appearance and behavior of text elements in almost any way, enabling you to achieve fine-grained control over text content in your PDF—something that simply wasn’t possible with iText 5’s Chunk class.
A Closer Inspection With RUPS
For a more visual representation of the differences, we can look at our two PDFs in RUPS to compare them. Developed by our Research Team, RUPS is iText’s specialized PDF debugging tool that displays the internal structure of a PDF, allowing developers to inspect the PDF syntax, objects, and their properties for analysis. We use RUPS frequently during development, and to assist our customers in diagnosing issues with specific documents. If you ever need to deal with buggy or malformed PDFs, RUPS is an essential part of your developer toolbox. Regularly updated with new releases of iText Core, RUPS is also open source and available on GitHub.
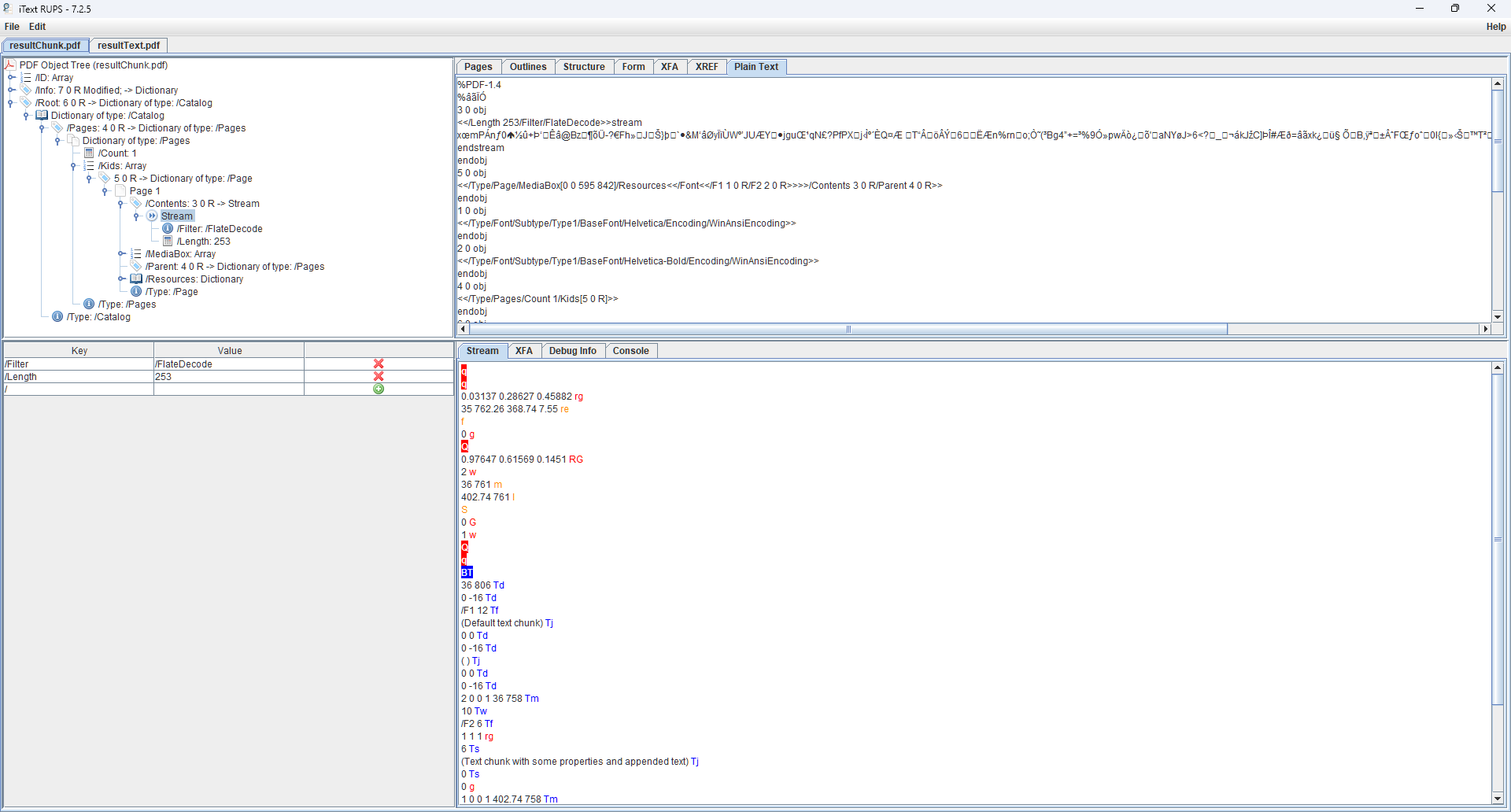
Looking at resultChunk.pdf in RUPS we can see how the PDF syntax is displayed in a hierarchical PDF object tree view in the top-left pane. Using this view, we can drill down through the objects to inspect their properties, such as the object ID, type, and other relevant information. The right-hand pane can display useful information such as the cross-reference (XREF) table or form fields, however, for this example the plain text view is selected.
More interestingly though, is the view in the lower-right. This shows the decoded raw data of the PDF content stream that contains all the PDF page description commands for the page. We’ll just concentrate on the part beginning with BT which defines the beginning of a text block, followed by the text positioning coordinates (Td), and then by the font settings (/F1 12 Tf) for our text chunk. There is only a single text block, so every font or styling change must be chained before the end of the text block (ET).
Now, let’s compare with the equivalent view of the PDF generated with our latest release of iText Core version, 8.0.1:
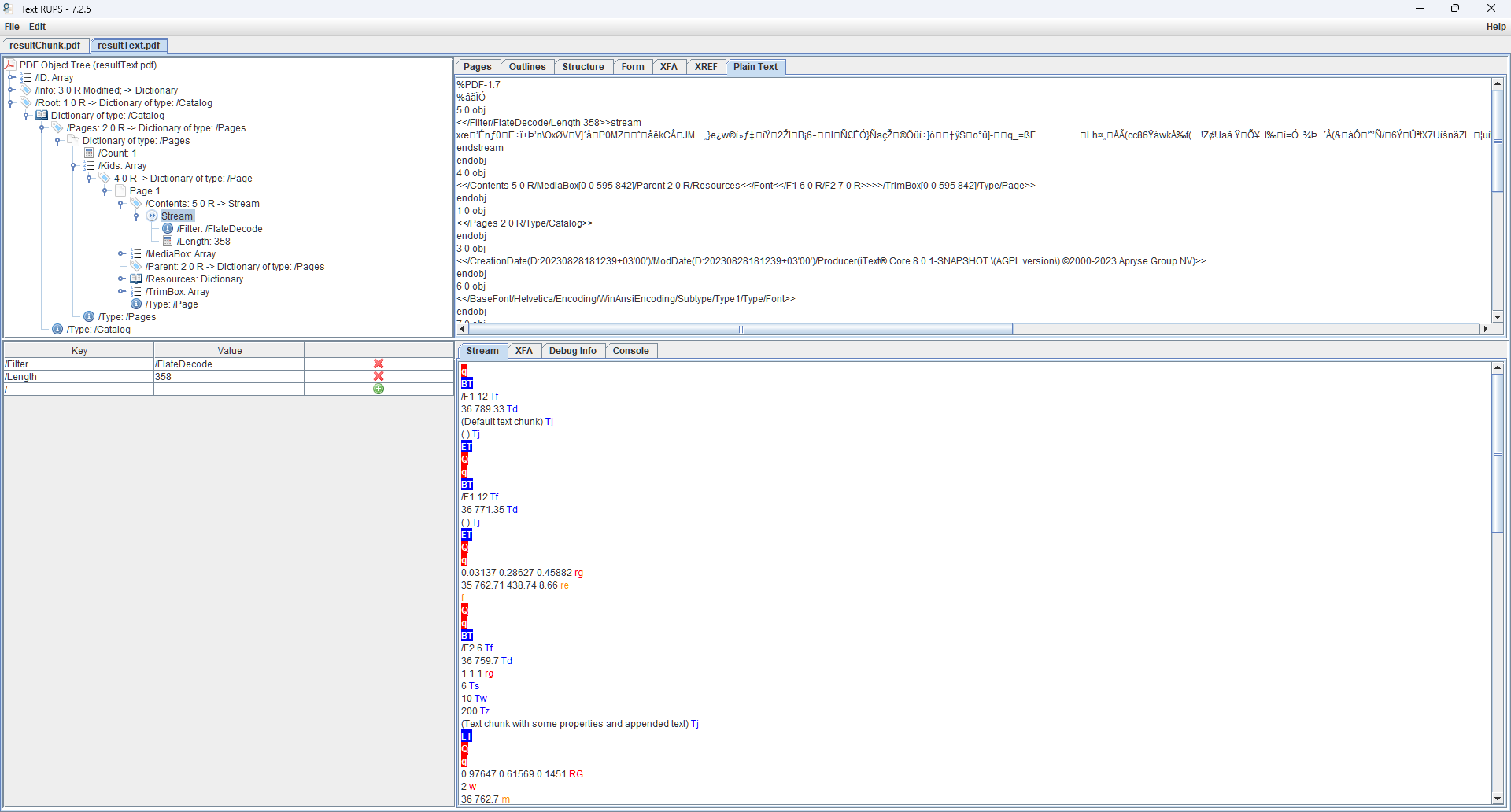
In this PDF, rather than a single text block we now have multiple blocks with their own individual layout and styling. In fact, to make it clearer let's do a side-by-side comparison of the two uncompressed content streams in RUPS.
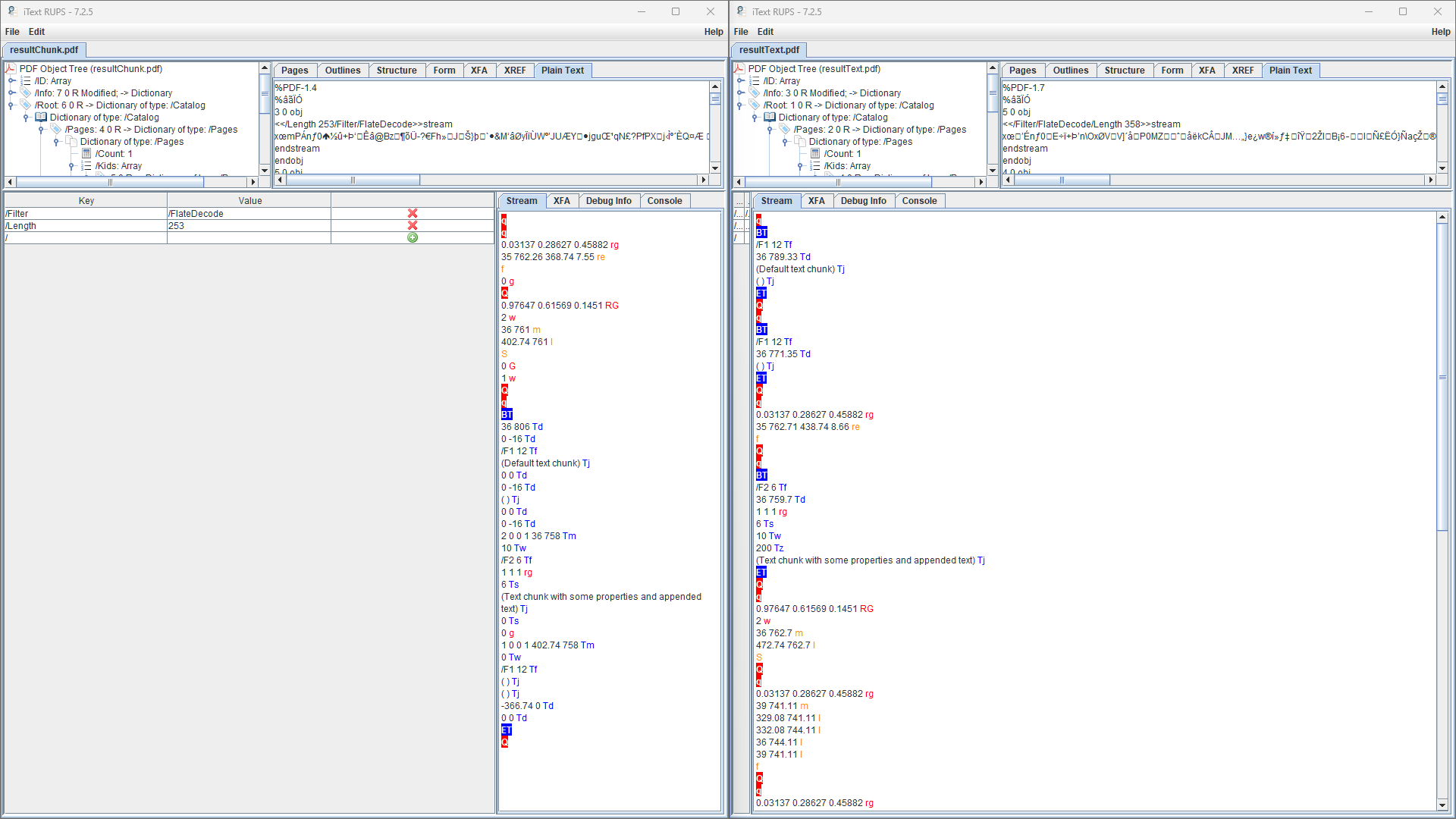
As we can see from looking at the two content streams, the result is a far more logical and simpler to follow PDF structure, as well as cleaner and more easily maintainable code.
Conclusion
While both the Chunk and Text classes provide mechanisms for creating stylized text in PDF documents, lessons were learned during the development of iText 7. While the Chunk class offered comprehensive text manipulation capabilities, it often led to verbose and complex code. When we introduced the Text class though, we wanted to streamline the way you configure and apply text styling. In addition, with the new custom renderers in iText Core, it opened the doors to more advanced customization.
The usability and behavioral improvements over iText 5 are not limited to the Text class of course, and recent articles have already talked about iText 8’s support for PDF 2.0 encryption methods, the latest digital signature extensions, built-in FIPS 140-2 capabilities and more. In future articles, we will look more closely at other benefits iText 8 offers to developers, although one thing that hasn’t changed is iText retains the same dual licensing scheme as iText 5—AGPL and commercial—so the open-source developer community gets exactly the same iText Core capabilities as multi-million dollar corporations.
For a quick rundown, you can see a list of the features in iText Core version 8 and the add-ons available in the iText Suite, and how it compares to what iText 5 offered. For developers who want to get up to speed with iText 8, check out our Java and .NET tutorials, and you can find plenty of examples and FAQs on the iText Knowledge Base along with release notes and other documentation. Don’t forget, you can also get a free 30-day trial of the entire iText Suite while keeping your intellectual property safe under the terms of our commercial license.
Happy coding!
