
To celebrate the New Year, Apryse is proud to announce the release of iText Suite 9.5: incorporating iText Core 9.5.0, and various updates to the add-on modules which make up the iText Suite. Open‑source libraries like iText serve a critical role in keeping the PDF ecosystem modern, interoperable, and future‑proof. This release underscores that responsibility by adding early support for Brotli compression and post‑quantum digital signature algorithms, together with improvements to PAdES signature validation.
As always, you’ll find full details on all new features, improvements, and bug fixes in the release notes for iText Core and its add-ons in our Knowledge Base.
iText Core 9.5.0
Support for Brotli Compressed PDF Streams
PDF allows various methods for compressing data streams, known as “filters”. Some filters (such as DCTDecode, JPXDecode, and JBIG2Decode) are image-specific filters using “lossy” or “lossless” compression, while others (RunLengthDecode, LZWDecode and FlateDecode) are general-purpose “lossless” compression filters suitable for text, vector data, and a wide range of PDF content.
Of these general-purpose compression types, Deflate/Flate compression (introduced in PDF 1.2) has become the standard for general-purpose PDF compression. Despite being over 30 years old, it performs well across various types of PDF content. In fact, the underlying technology is even older than that, since Deflate compression uses the Lempel-Ziv (LZ77) algorithm along with Huffman coding, dating from the 1970s and 1950s respectively. Despite its age, Deflate remains efficient and forms the basis of the ubiquitous ZIP archive format used across virtually all platforms.
However, compression technology has advanced significantly. Modern codecs used for audio and video enable enormous size reductions, though many of these approaches are inherently lossy and therefore unsuitable for compressing text, fonts, vector graphics, and other precision‑sensitive PDF content. On the lossless side, formats like FLAC, ALAC, PNG, and more recently AVIF/HEIC (which support lossless modes) show how much progress has been made in achieving better ratios without sacrificing fidelity.
The Brotli compression algorithm is a more modern compression algorithm that builds on similar principles as Deflate, with some key improvements. Developed by Google and finalized in 2016, it was originally developed to reduce the size of fonts transmitted over the Internet. Nonetheless, it can be applied to the same wide variety of use cases as Deflate while typically achieving better compression ratios.
For a closer look at the proposals to include it in the PDF specification, the PDF Association has two excellent articles on the subject: Brotli compression coming to PDF and Understanding Brotli PDF Compression which go into detail on the background of Brotli and comparisons to Deflate, and how it should be implemented in PDF.
Decompression of Brotli streams is supported out-of-the-box; however, as Brotli compression will soon be part of the PDF specification iText Core needs to support not just reading Brotli-compressed PDF streams, but also writing them. Therefore, we’re pleased to introduce the new brotli-compressor module to enable this functionality.
Because Brotli support is not yet standardized and is not widely implemented across current PDF processors, the module is only available from our artifactory, and so should be used cautiously until formal standardization and broader ecosystem support arrives.
The following image shows some results of our internal testing using the Brotli filter and the standard Flate filter for different workloads. The tests show results of normal compression (NC) and high compression (HC) for text and table content, with the Y axis showing file size in KB.
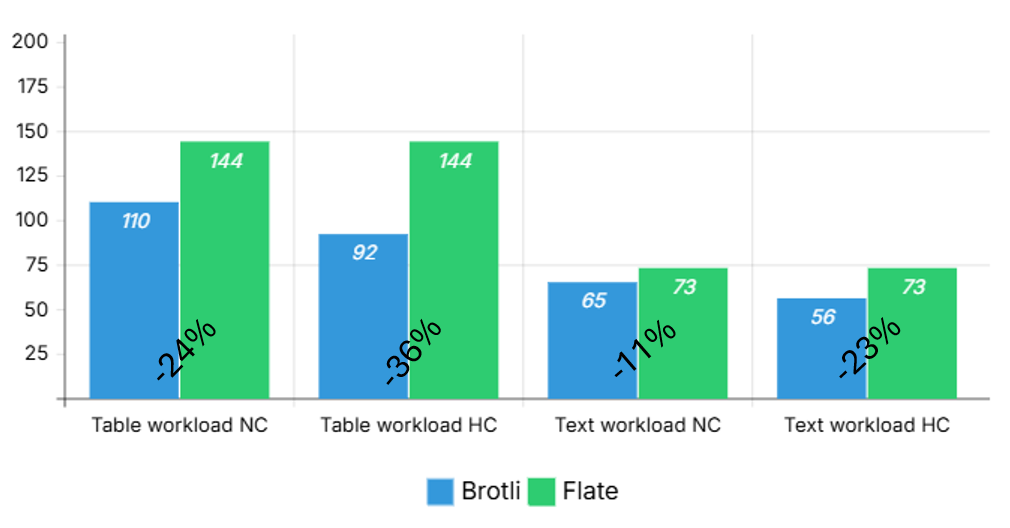
For details on how to enable the Brotli compression support, refer to the relevant section in the release notes. Alternatively, we've written an article for the PDF Association on iText’s implementation of Brotli compression if you'd like to learn more.
Post-Quantum-Safe Digital Signature Algorithm Support
While quantum computing is still in its early stages, it creates a real long‑term security concern known as “harvest now, decrypt later.” In this scenario, attackers collect encrypted data today and store it until a future quantum computer becomes powerful enough to break the encryption.
No one knows exactly when such cryptographically relevant quantum computers will arrive, with estimates ranging from several decades to potentially just a few years. As a precaution, cryptography experts have been developing post-quantum cryptography (PQC) algorithms designed to resist both classical and quantum attacks. There’s a great explanation of what post-quantum cryptography is on the National Institute for Science and Technology site.
Most of today’s public‑key encryption relies on mathematical problems that are easy to perform in one direction but extremely difficult to reverse. For example, multiplying two very large prime numbers is fast, but factoring the result back into those primes is so computationally intensive that it would take classical computers thousands, or even billions, of years.
Regular computers use bits, which can be either 0 or 1. Quantum computers, by contrast, use qubits, which can exist in a combination of both 0 and 1 at the same time through a quantum effect called superposition. Qubits can also become entangled, meaning their states are linked in ways that have no classical equivalent. These properties allow quantum computers to process many possibilities within a single computational step.
For example, while two classical bits can represent only one of four possible combinations at any moment, two qubits can exist in a superposition of all four combinations at once. Three qubits can represent eight combinations, four can represent sixteen, and so on. This results in an exponential growth in the size of the quantum state space. This exponential scaling, combined with specialized quantum algorithms such as Shor’s algorithm is what makes cryptographically relevant quantum computers a potential threat to the encryption typically used for PDF digital signatures.
However, the PDF industry is taking proactive steps to ensure digitally signed PDF documents are safe from these risks. At the PDF Association’s PDF Days 2025 event, an agreement to integrate quantum-resistant signatures into the PDF specification was reached. Among the post-quantum cryptographic standard approved by NIST are two digital signature algorithms: ML-DSA (Module-Lattice-based Digital Signature Algorithm) and SLH-DSA (Stateless Hash-based Digital Signature Algorithm).
Since official support for these algorithms will soon be added to the PDF specification, you can rest assured that iText is fully prepared for these developments. As such, iText Core 9.5.0 includes a proof-of-concept implementation for both the creation and validation of post-quantum digital signatures in PDFs. You can read more about this implementation in the Knowledge Base article and learn how Apryse’s active participation in the PDF Association’s technical discussion will ensure our final implementation fully aligns with the official standard. We’ve also prepared Java and C# code examples which you’ll find linked in the above article.
We’re committed to evolving this proof of concept into fully robust, standards‑compliant support as soon as the PDF specification is finalized. With the quantum threat approaching, iText ensures you’re building on a platform prepared for the future.
Enhanced PAdES Signature Profile Validation
Our goal of making the task of digitally signing and validating PDF documents with iText easier continues with enhancements to preset PAdES signature profiles. The PAdES profile validation is improved and can detect when the Document Security Store (DSS) changes between revisions, improving timestamp validation accuracy.
Also in this release you'll find new samples for the Ukraine and Moldova trusted lists which are available from the European Commission's eIDAS Dashboard site.
Bug Fixes and Miscellaneous Improvements
We have introduced a common, cross‑platform JSON AST and converters to serialize/deserialize between Java/C# objects and a unified JSON representation, improving maintainability and GraalVM/AOT support. We also added support for East Asian (Japanese) line‑breaking rules in the layout module, improving typography for Japanese text by avoiding orphan punctuation at the beginning of lines.
We also resolved a number of both customer and internally reported bugs, such as an issue with form filling and flattening, and a bug in calculating the maximum number of XRef elements in large documents. We also fixed an issue preventing OCG layers from being added, modified, or removed in append mode, and resolved an issue in handling unencrypted metadata in encrypted documents.
A bug in PDF signature validation was resolved, where iText did not use OCSP/CRL responses added in non-timestamped revisions. We also fixed a NullPointerException for Java, where the robustness of structure tree handling after document merges was improved.
For more details on other improvements and bug fixes, see the release notes for Core and the add-ons on the Knowledge Base.
pdfCalligraph 5.0.5
In addition to changes to maintain compatibility with the iText Core 9.5.0 dependencies, a fix was implemented to improve memory usage in long-running environments. This was caused by an accumulation of events in the ProdEventHandler component, and so the event handling logic was updated to clear once a PDF generation job has completed.
pdfHTML 6.3.1
An issue was resolved with inconsistent handling of inline elements when converting HTML tables with the page-break-inside: avoid CSS property. In addition, we fixed two occurrences of NullPointerException errors when converting ordered lists.
A bug caused by an interaction problem between the behavior of the layout renderers was resolved, which could result in specific layout issues causing an infinite layout loop. We also fixed a font size bug, and a regression with Japanese charset detection.
pdfXFA 5.0.5
For this release, a customer-reported bug was fixed where a rare infinite loop when laying out certain large text fields across multiple pages could occur.
Patch Releases for Compatibility
pdfOCR 4.1.2
Patch release to maintain compatibility with iText Core 9.5.0 dependencies.
pdfOptimizer 4.1.2
Patch release to maintain compatibility with iText Core 9.5.0 dependencies.
pdfSweep 5.0.5
Patch release to maintain compatibility with iText Core 9.5.0 dependencies.
Pull Requests
For this release we want to thank dajoropo for their contribution to improve error handling when an attempt to create a PDF from a TIFF image fails. Now, iText Core will include the original exception to assist in diagnosing why the error occurred.
Please feel free to visit our GitHub if you want to contribute to iText.
RUPS 26.01
We’ve also just released the latest version of the RUPS (Reading and Updating PDF Syntax) PDF diagnostic tool. RUPS is extremely handy for PDF debugging purposes, and this latest version introduces Brotli compression support, and the ability to manipulate stream filters. In addition, to add to the support for ASN.1 data structure for digital signature objects from the previous release, this version adds support for the ISO/TS 32004 MAC extensions.
There’s also a number of bug fixes and quality-of-life improvements. Make sure to check out the linked release notes for full details.
Showcase PDF
As always, we’ve made the iText Core release notes into a showcase PDF document. Not only does it conform to the latest PDF/UA-2 standard for accessible PDF documents, as well as the PDF/A-4F archiving standard, it’s also digitally signed. You can find the source code and resources required to recreate the document yourself embedded.
But that’s not all, as we’ve created a public repository where you can find an example .NET project to automatically generate accessible PDF documents from suitable web pages, applying the correct fonts, injecting custom content, generating a table of contents, and more.
Have fun!
Get Started with iText Suite 9.5
If you’re completely new to iText, we highly recommend our free 30-day trial. This lets you try out the entire iText Suite: so not just iText Core, but also all our open and closed source add-ons, completely free.
And because the trial is covered by the terms of our commercial license, you can rest assured your intellectual property is safe. The AGPLv3 conditions do not apply to commercial license holders, so your code can remain closed-source if that is a concern for you.



