Pdf2Data is a tool that allows for structured data to be extracted from similarly structured text documents. The way that this is done is through the use of rules to define the location of text that should be extracted or the format of the text. Through the rest of this blog post I’ll describe the basics of how it works and then show how it works with a simple example.
To begin, let's look at how the rules are defined to choose the text you would like extracted. You can define the areas with either, the pdf2Data web app, or with Adobe reader's comment feature. Once you have selected the area, you run the templates through pdf2Data programmatically, using rules to describe what needs to be extracted within a template. Then the information is passed to the extractor, which is shown in the code example below:
Pdf2DataExtractor extractor = new Pdf2DataExtractor(template);
To create the template PDF, all that needs to be done is to define the areas of interest within the PDF. This can be done through either the online demo or through the commenting system of Adobe Reader or Acrobat.
These selection rules come in many different varieties. A couple of examples include the font style selector, which selects only text which has the same font style as the highlighted field, the geometric boundaries selector which extracts the text that is inside the boundaries created by the geometric shape, and the text pattern selector, which selects only text that matches a given pattern with the option to include preceding or trailing text around the selected text. These rules allow the templates to be flexible, simple, and powerful, and more are being continuously added. They allow a user to define a relatively small number of rules and still be able to extract all of the pertinent information from the document. Many documents that have a similar template do not always have the exact same spacing within the document but the contents are always arranged in the same pattern. Due to the abilities of these selectors, the correct information can always be retrieved from documents with similar templates.
Once you have the rules that describe what text you want extracted from your PDF, the actual extraction is very simple. It can be done by installing the pdf2Data web archive file onto a Tomcat server, the steps to do being described here. or done programmatically with only a few lines of code as shown here:
Pdf2DataExtractor extractor = new Pdf2DataExtractor(template);
extractor.parsePdf(sampleFile, targetPDF, targetXML);
Now that we’ve gone over the basics I’ll walk through the demo and show how simple it can be to create a template and extract all the information that is needed from a set of documents. The demo that I will be using can be found here. The first thing that needs to be done is to upload a PDF that is similar to, or is one of the PDFs that you are going to want to extract text from. From there, you start to define the rules for how the text will be extracted through the GUI provided.
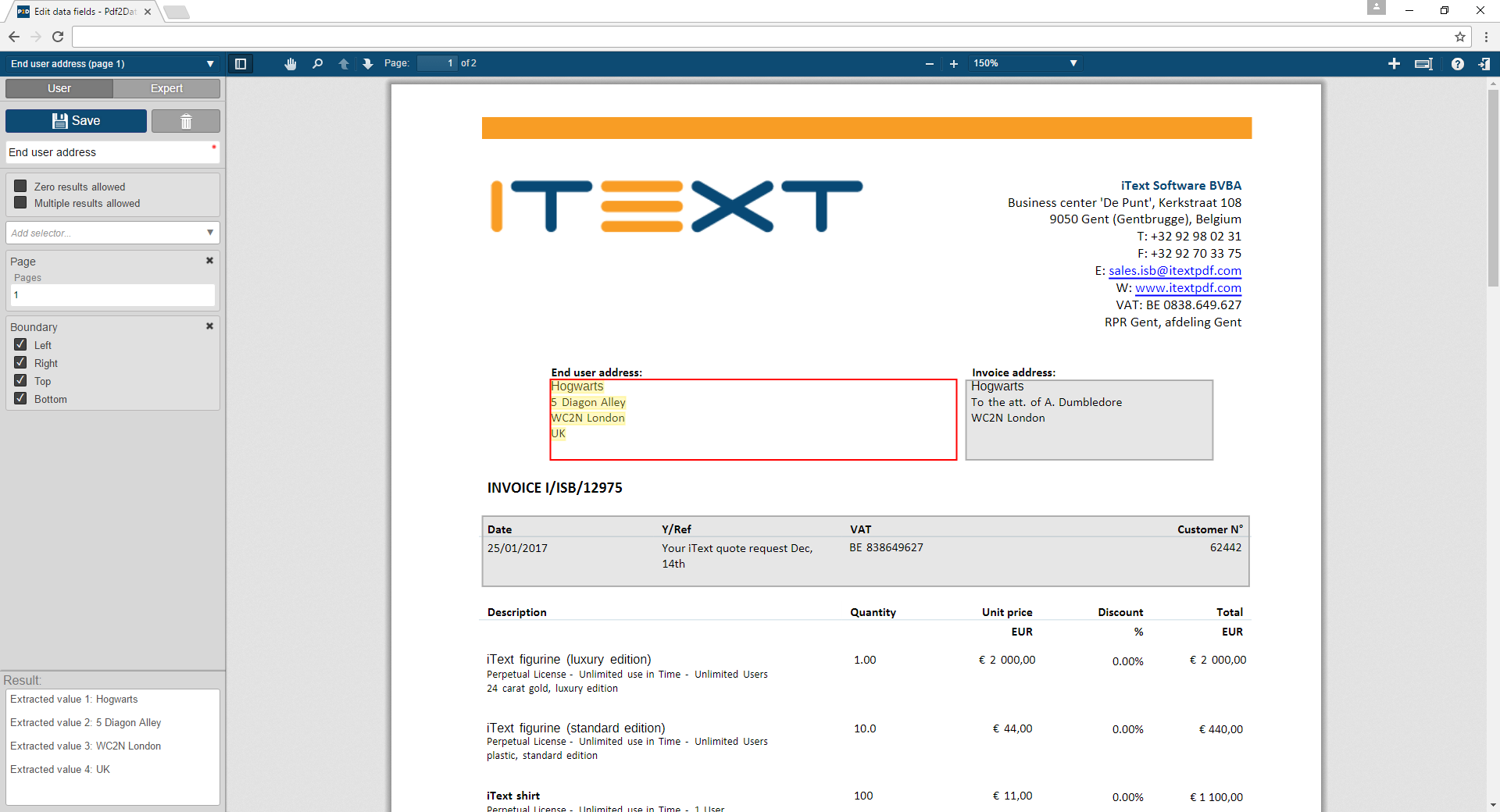
Again, this can be done just through Adobe reader with comments. Using the GUI makes the process simpler by providing the names of the selectors that are available and providing check boxes for the options instead of them having to be used through text codes as done in a regular comment. Below is a rule that I have created through a regular Adobe reader comment that has the same functionality as the one that is pictured above that has been created through the GUI.
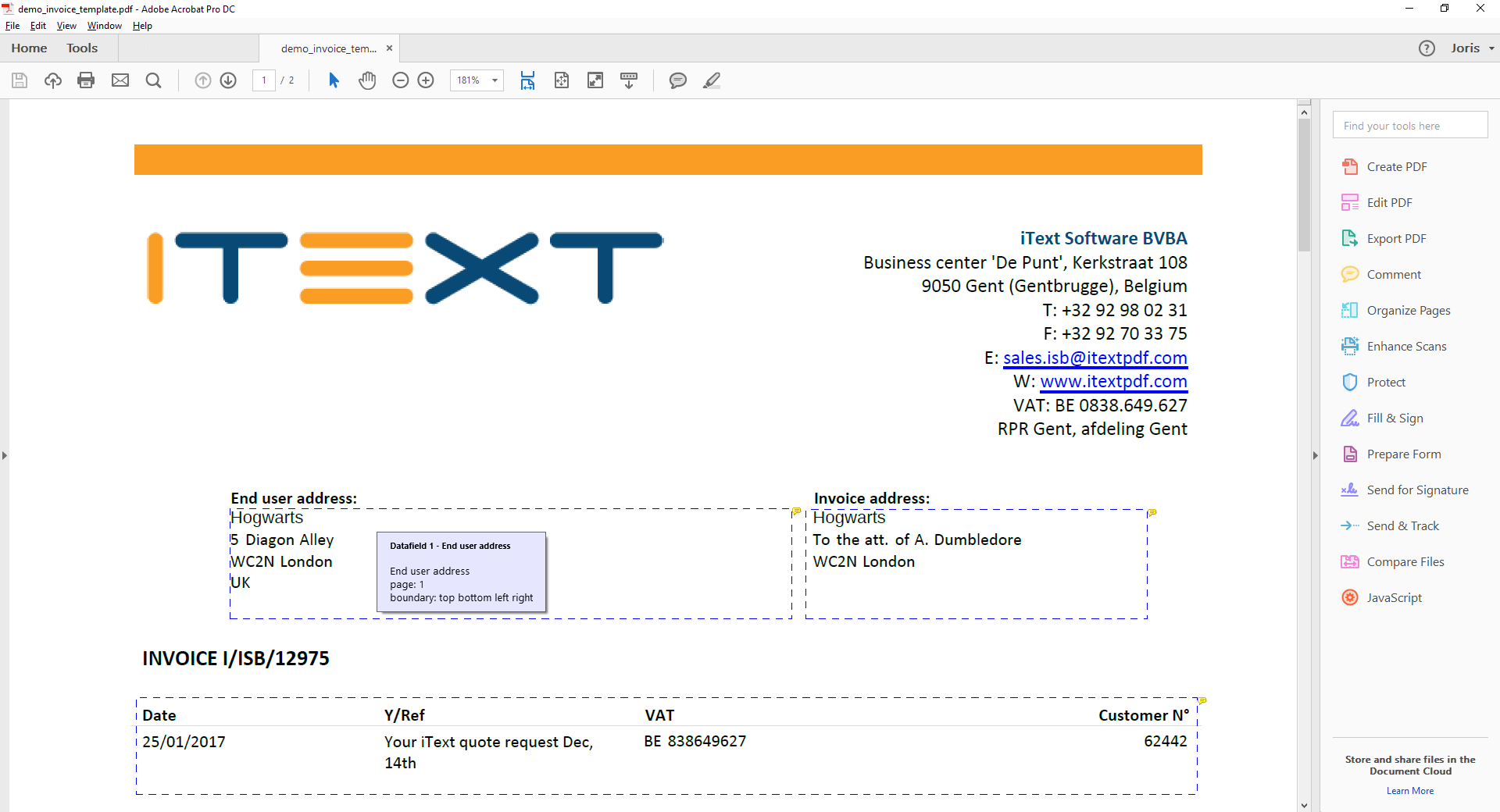
All that is needed to define the same rule in Adobe reader is to highlight the area that is to be extracted and describe it in the comment. The name of the comment is what is put on the first line, in my example it is Date, and this can be set in the properties of the comment in Adobe Reader. The second and third lines describe the selectors that will be used to define what text in the field is to be extracted. In my case, I want the text that in inside the top, left, bottom, and right boundaries and is in the format of a date.
We can continue defining rules until we have selected all of the text that is important in the PDFs that we will be extracting from. Once we do that, all that is required is to upload additional PDFs and make sure that the rules that have been defined extract the information that we are looking for. After the testing of the template is to your satisfaction you are then able to use this functionality in your workflow to extract the important information from thousands of documents without any additional manual steps.
pdf2Data is a great tool to be able to unlock the data that is hard to access within PDFs. The definition of a template PDF can be done through either the online demo GUI or through the Adobe Reader commenting tool. Whichever way you decide to do it, pdf2Data will allow you use that template and easily implement extraction of vital information from PDF documents in your workflow.
See the recording of our webinar on pfd2Data of April 19, 2017.


