We’ve talked before about the PDF/UA specification, both how to achieve compliance with legislation and the importance of improving access to information to people with disabilities. Yet there’s more to PDF/UA than making life easier for a certain section of the population, or even just for humans. We can also make life easier for machines too…
Recently, our Technical Product Manager André Lemos gave an intriguing talk at NDC Sydney (a .NET developers conference), called “Access All Areas: Making Accessibility More Accessible”. You can watch the video below:
In this presentation he showed that making documents that conform to PDF/UA standards doesn’t just make them more accessible to people, but also for technologies such as screen readers and the growing number of virtual assistants like Alexa, Siri, the Google Assistant and Cortana.
We also have devices and gadgets that are becoming smarter; mobile phones, cars, watches etc. which come with these technologies built-in. As these technologies improve and become more widespread, we can utilize them in more and more ways to enhance our consumption of written media, whether it’s in PDF format, HTML, DOCX etc.
As an example, it’s now possible to ask Alexa to read you a book. Or, at least it’s possible for Alexa to read certain books from your Audible or Kindle library. Alexa can only read the books that have the feature “Text-To-Speech” enabled, as these books have been carefully produced to allow it to be able to understand the contents of the book. That is to say, the content will meet similar standards to the PDF/UA requirements such as suitable alt text for images, defining the natural language of text etc.
However, there are countless numbers of books in PDF format which don’t conform to these requirements, not to mention other documents like articles, reports, scientific papers etc. In 2015, Phil Ydens, VP of Engineering for Adobe Document Cloud made a conservative estimate that there were 2.5 trillion PDF documents in the world. How many of them can be classified as accessible?
Today, approximately 15% of PDF files include tags for accessibility. A far smaller percentage are tagged well enough to be considered accessible, even though it's been possible to make PDF documents accessible since 2001. Fewer still are tagged in conformance with PDF/UA, the gold standard for PDF accessibility.
Duff Johnson - The day the ADA came to web content
The above quote comes from a PDF Association article discussing the recent US Supreme Court ruling against Domino’s Pizza, which upheld a lower court’s decision that the inaccessibility of Domino’s Pizza websites constituted discrimination under the Americans with Disabilities Act. It’s well worth reading the article to better understand the ruling and its implications, though as the article points out this does not just apply to websites and mobile apps using HTML/CSS/JavaScript, but also to any PDFs and other file formats available on a website.
So, what can be done to resolve this? It could be argued that it’s technically possible (if impractical) to manually review and edit all the PDFs out there to conform to the PDF/UA standards; however, surely there’s a better way?
Well, the aim of this article is not to magically solve this problem (sorry). However, we are going to discuss a few ways to get closer to this seemingly insurmountable goal, by using iText and a host of AI technologies. We’ll also be using a PDF Accessibility Checker, a free tool that enables experts and testers to review the accessibility of PDF documents and forms. It was created by Access for All, a Swiss non-profit foundation for promoting technology adapted to people with disabilities.
A simple problem
You’re probably all familiar with the following standard typography test, a sentence which uses all the letters in the English alphabet (or pangram):
“The quick brown fox jumps over the lazy dog.”
Now, let’s imagine a PDF document that looks like this:

You can probably guess the problem here. To a normally-sighted human, this can be read exactly the same as the text-only version. Conversely, to someone using a screen reader this is not the case as there is no alt text for either image. During André’s presentation he asked the audience what would happen if we told Acrobat’s built-in screen reader to read the PDF.
If you guessed “The quick brown image 1 jumps over the lazy image 2” you’re close, but if you instead guessed “The quick brown jumps over the lazy”, then give yourself a cookie. Of course, this is because the screen reader in Acrobat will simply ignore images without any alt text or a description.
In fact, let’s take a closer look at our PDF in the PDF Accessibility Checker:
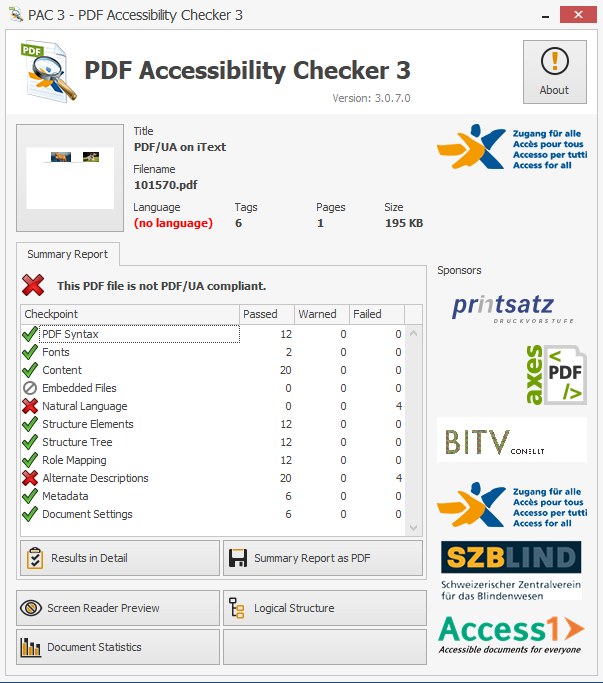
Straight away, we can see some problems with this document. It was created in iText in preparation for the presentation André gave, and so many of the conditions for PDF/UA compliance have already been met. To reach full compliance though, it requires alternate text for images, and the natural language must also be specified. Traditionally, this information would be added manually either during PDF creation or after the fact (as shown in this example) though this would take significant time and effort. As clever and resourceful developers though, we don’t want to do that. Instead, can we use machine learning technologies to make this document PDF/UA compliant?
Image recognition
First of all, let’s look at images. Correctly tagged images are an essential part of the PDF/UA requirements, and one of the most common compliance failures is documents not having any alt text or an alternate description for images. Software such as Acrobat, Microsoft Office etc. now come with built-in accessibility checkers in that warn you if you create a document with missing information for images, yet still require user intervention to add this information. And of course, that doesn’t affect documents that have already been created.
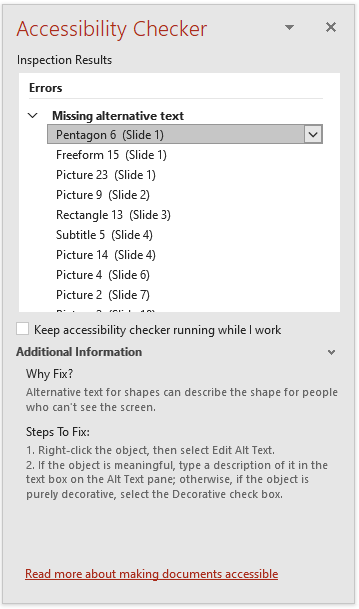
So, what can we do about this? In the presentation, André demonstrates how you can program iText to query Microsoft’s Computer Vision API and get it to return an array of single word tags for images or a descriptive caption. By using the cloud-based image recognition that Microsoft (and others) can now provide, we can now simply get information about an image and solve the alt text problem!
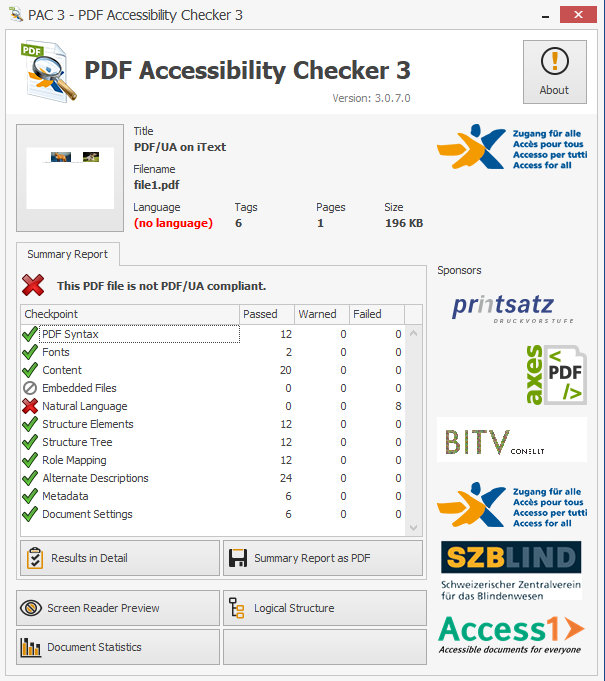
The PDF Accessibility Checker now shows the missing alternate description issue has been resolved, resulting in a nice green checkmark:
The PDF Accessibility Checker has a handy built-in tool called “Screen Reader Preview”, so let’s use it to take a look at our PDF now:
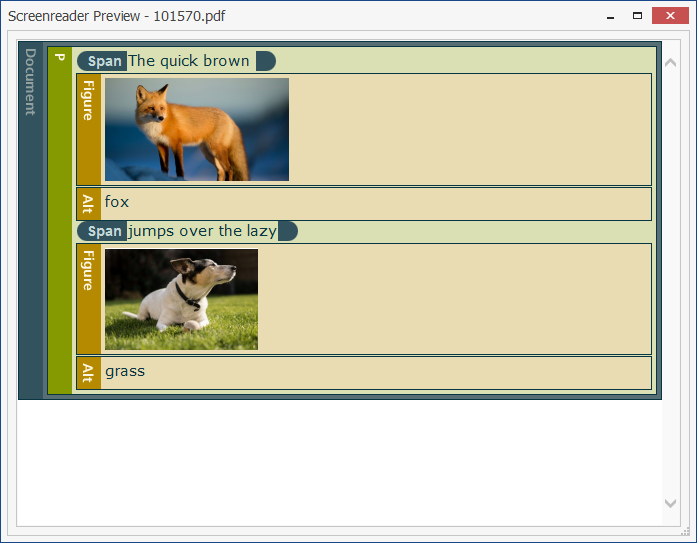
Hang on, that’s not right. “The quick brown fox jumps over the lazy grass”? It’s clearly a picture of a dog, not grass. Or rather, it’s both a picture of a dog and some grass, but that’s not exactly what we wanted.
Interestingly, if we use the same method to get an image caption instead, then we see that it returns “a brown and white dog sitting in the grass”. That’s certainly more accurate as a description, yet both results illustrate the importance of context when tagging documents. Contextually, the single word tag is more appropriate for this particular document, even though it’s inaccurate.
If you’ve watched the video of André’s talk however, you’ll know that although the first tag that the Computer Vision API returned was “grass”, the second one was “dog”, which is more than a little frustrating. So near, and yet so far!
Still, a semi-accurate description is better than no description, right? Well yes, but while we can currently use image recognition technology to save our time by automatically finding alternate descriptions for images in a PDF, it’s not perfect and will still require human verification...at least for now.
As image recognition technology using machine learning improves, with it will also come better contextual understanding. Both Google and Amazon offer their own competing image recognition services, and the ability and accuracy of these technologies will only continue to grow.
Language recognition
What else can we use to make our PDF more accessible? Another of Microsoft’s Cognitive Services is their Translator API, a neural machine translation service that developers can integrate into their applications. André’s demonstration showed how we can use iText to access this API to detect the natural language of a PDF and populate the relevant fields. This is more reliable than the image recognition as Natural Language Processing (NLP) is a more mature technology, and while it’s by no means perfect, anyone who has used online translation services like Google Translate will know the improvements that have been made over the years. Providing the language of a document is the same throughout the whole document, then this method can be used to meet another of PDF/UA’s requirements.
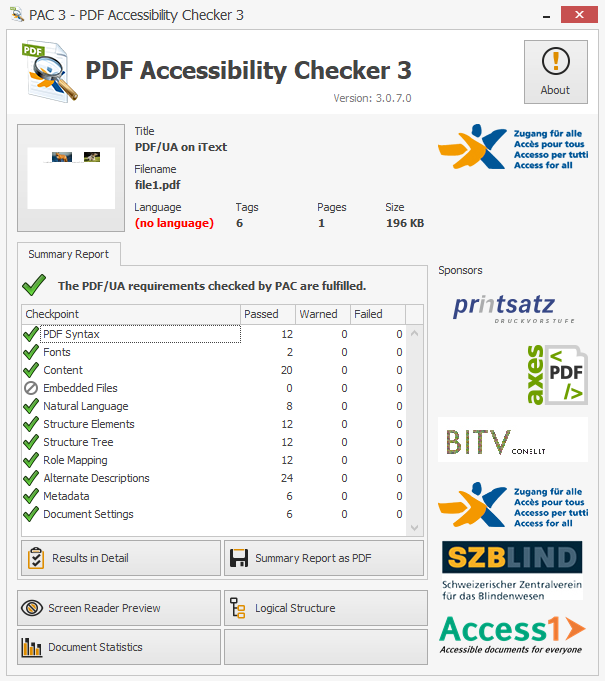
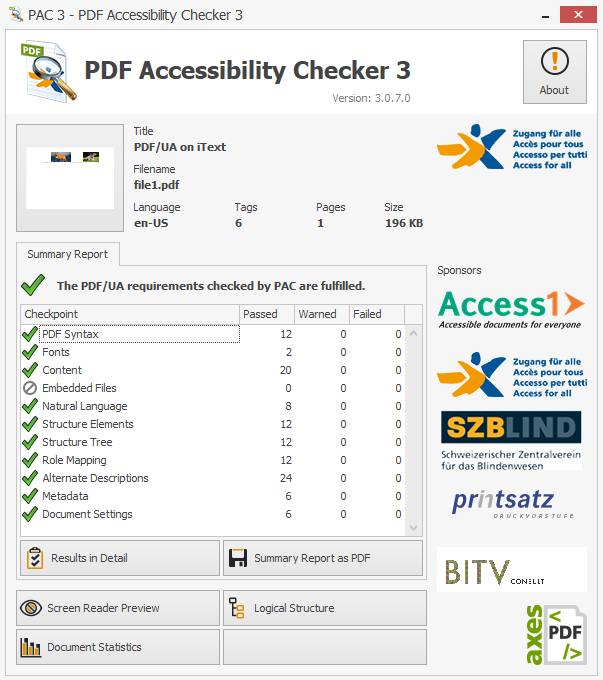
Although our PDF now complies with the PDF/UA requirements, you might have noticed from the screenshots that the “Language” of the PDF is not specified. This is part of the document’s metadata and relates to the /Lang entry in the document catalog of a PDF. Although it’s not required to meet the PDF/UA specification, since we have already determined the natural language of the content in our PDF, we can use the same string to set the document’s language to (in this example) "en-US".
What could be achieved in the future?
As these technologies develop and become more powerful, so do the potential applications for machine learning in the accessibility arena. While machines may not replace the need for human intervention to achieve accessibility standards (at least in the foreseeable future) they can certainly be of assistance. There are already steps towards integrating machine learning using cloud technology into PDF accessibility checking software, and as contextual understanding and AI capabilities improve it will be able to help with more complex issues such as understanding the correct reading order in PDFs, or perhaps even resolving color contrast issues that impede usability for people with visual disabilities like color blindness.
One additional way that machine learning can help to make information more accessible is by content simplification. People with cognitive or learning disabilities can have problems digesting lengthy content, and it can be helpful to reduce it down into smaller, more digestible pieces. IBM's Content Clarifier uses their Watson AI technology to do just this. However, this approach doesn’t just help people with disabilities, it can also help people who either don’t want to read a 1000-word article, or simply don’t have time.
A simpler example of similar technology can be found on Reddit, where you might have encountered things called “bots”. A bot is a program capable of understanding a query (question, command, order, etc.) and deliver the appropriate response (answer, action, etc.) using the Reddit API.
One such bot is the AutoTLDR bot (if you’re familiar with Reddit, you might know its users are notorious for replying to lengthy posts with “tl;dr” (for “too long; didn’t read”), and it works by automatically creating a summary of specific content such as news articles. It uses the SMMRY API which is a configurable algorithm to summarize articles and text by reducing it to only the most important sentences. It’s interesting to note that the SMMRY API does not just work for HTML web content, it can perform its magic on PDF and TXT files you upload.
So, if you don’t have time to read Stephen King’s It (which weighs in at around fourteen hundred pages), perhaps you could ask Alexa (or your favorite virtual assistant) to summarize it for you? Book reviewers, take note…
Resources
If you’d like to play around with the .NET project André demonstrated at NDC Sydney, or even develop it further, you can download it from our repository.


