
At iText’s customer event I learned a great deal about what iText is working on, and I also heard how people are using our products and what they have been able to create. After seeing what RadBee had built, I was eager to learn more about how iText users can make the most out of their documents. When you’re making a cocktail, you can choose the ingredients so that it tastes the way you want. Following that theme, Uladzimir Asipchuk and Yulian Gaponenko from our iText Development Team shared 5 ingredients that you can use to help you make the most of your documents.
1. The A, B, and C to make a simple and effective table of contents
A well-designed table of contents is the basis of many documents. At first glance this may seem a bit too simple to give tips on, but Uladzimir explained that performing this task is a great way to understand the iText 7 Renderer Framework. The iText layout engine consists of two hierarchies; one starts with the IElement interface (Java/.NET) and the other with the IRenderer interface (Java/.NET). The IElement interface is implemented by classes such as Div, Paragraph, and so on. Creating a PDF document usually means creating several instances of these classes, customizing their properties, and finally adding them to a document.
Under the hood though, iText separates with instances of the IRenderer hierarchy. For each of the mentioned classes there’s a corresponding renderer class. For instance, the Text element corresponds to TextRenderer (Java/.NET), and Paragraph to ParagraphRenderer (Java/.NET). These renderers are responsible for the layout and drawing of elements.
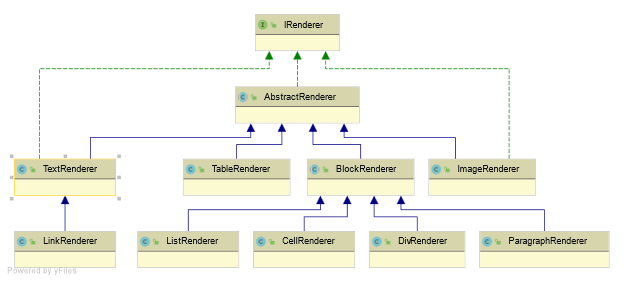
Uladzimir goes onto show how you can easily subclass these renderer classes and tweak their default behavior. Using the table of contents as an example, Uladzimir showed how you can save a page number to a title by subclassing using TextRenderer. After rendering all the titles with this custom TextRenderer, all that there is left to do to finish creating an immaculate table of contents is to collect the page numbers. These steps, like everything else Uladzimir and Yulian covered lend themselves to many other tasks that are needed to build your perfect PDF document.
2. The choice between optimal approaches vs. optimizing the results
For the second tip, Yulian discussed the usage of vector graphics versus of raster images, and how to use them optimally. He compared different approaches by showing code to do this by drawing graphical primitives like lines, arcs and rectangles on a PdfCanvas (Java/.NET), which is a very cumbersome process. He then demonstrated a much more convenient way by showing how SvgConverter (Java/.NET) can be used add an image to your document by reading an SVG file.
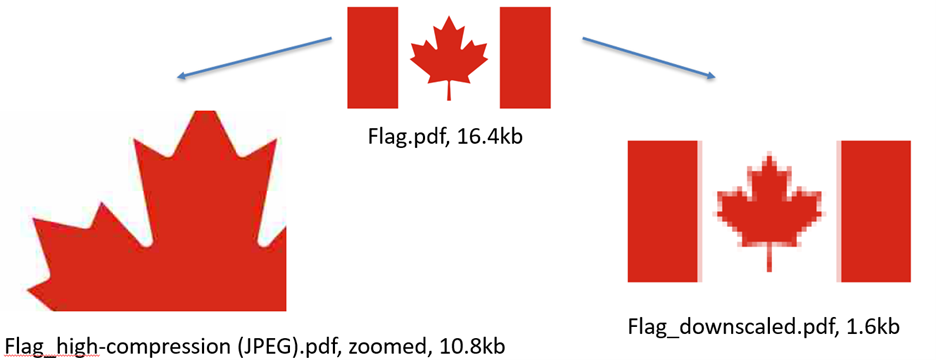
Another way to optimize the images that you use in your documents is by using iText's pdfOptimizer. This iText 7 Core add-on lets you easily optimize your PDFs according to various optimization profiles. In the example that can be seen above you can see what happens to your images if you compress or downscale a .jpeg file. PdfOptimizer can fix some of the mistakes by adjusting the contents in order to better fit the specific use case. Yulian also detailed how pdfOptimizer can also remove redundancy when merging or flattening documents. Even if some PDF documents are already optimized, merging them will often result in a document with duplicated resources. When this occurs even more opportunities for optimization arise.
3. Insights on how you can reach your documents users all over the world
Uladzimir continued with the third tip, about how to ensure that the fonts being used in your PDFs will be shown correctly. When you are writing Latin text using standard fonts the task is simple and this isn’t much of an issue, however when you need to write Arabic or Thai the task becomes a bit trickier. As you can see in the example below, if done incorrectly the text won’t be readable to a native speaker and your message will be lost. By simply adding just one dependency and using pdfCalligraph, this issue is resolved.
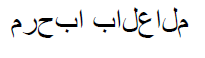
pdfCalligraph disabled
![]()
pdfCalligraph enabled
Uldazimir then went into more detail and showcased a feature of pdfCalligraph called TypographConfigurator (Java/.NET) and the features you can add when using it. This way you can create PDFs that can exactly match the needs of you and your customers. To configurate any text you will only need to specify the scripts, and the exact font features you want enabled. Now you can create amazing looking PDFs in symbolic languages or languages that read right to left.
4. Becoming a master in creating paged media
After this, Yulian shared with us the ins and outs of paged media. By using iText’s pdfHTML Yulian showed how easy it is to fine-tune pagination if you want to convert an HTML document to PDF. In your CSS file all you need to do is add a @media rule that specifies the appearance of the HTML document when it’s printed on paper, and with the @page rule you define the page’s dimensions and other basic properties. The only thing you need to think about in iText then is to set the media type to print in your converter.

5. The last ingredient is up to you
The fifth and final tip was not a technical one, but a reminder that iText is very active when updating our iText Knowledge Base and within the Stack Overflow community. You can also visit our GitHub to find a repository with all the full code examples from this presentation. All of these locations are great sources of knowledge to give you all the information you need to make the most of your PDFs.
These tips will surely help you make the most of your PDFs and we are interested in seeing what you are able to create. Next up you will be able to see another customer demonstration from this event. This time highlighting our collaborative document solution iText DITO, and how Wout Florin and his team at Cymo utilize the benefits of microservices to make life easier for their client Mateco.
This article was based on a talk given at iText’s 2022 customer event.