
Intro
XFA is still widely used despite the fact that it was deprecated in PDF 2.0 (published in 2017), and the last update to the XFA specification was in 2012. If you need to flatten XFA to PDF you can use our iText 7 add-on pdfXFA, but one of the challenges XFA documents present is modifying them before flattening. While it's fairly easy to modify them in an application such as Adobe LiveCycle Designer, modifying the JavaScript through code can be challenging, as some structure information is required.
Structure
The XFA document has a few different XML files, template, localeSet, xmpmeta, datasets, config, and xfdf. When modifying the JavaScript, the important file is template. This contains the structure of the XFA document including all the information about the fields and any JavaScript used, generally stored under a script or a calculate tag. In order to see the XML structure and navigate the DOM you can use RUPS, and access this on the XFA tab in the RUPS window. 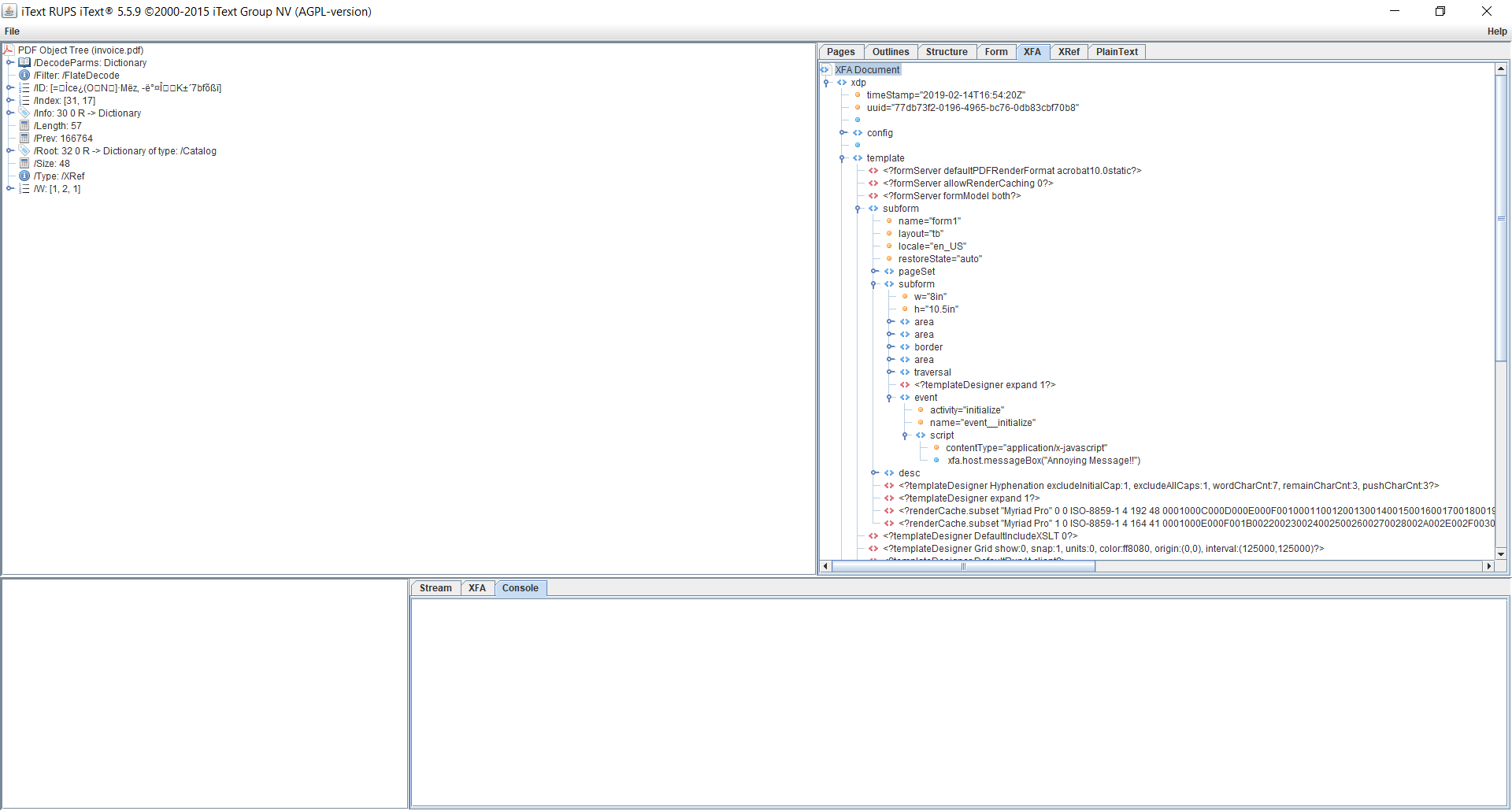
What can JavaScript Do?
Below are some basic examples of what JavaScript can do to an XFA form. Because there isn't a limit on the JavaScript, there are countless possibilities as to what can be achieved with JavaScript. Theoretically (although not very practically), entire applications could be written using just JavaScript and XFA.
Buttons
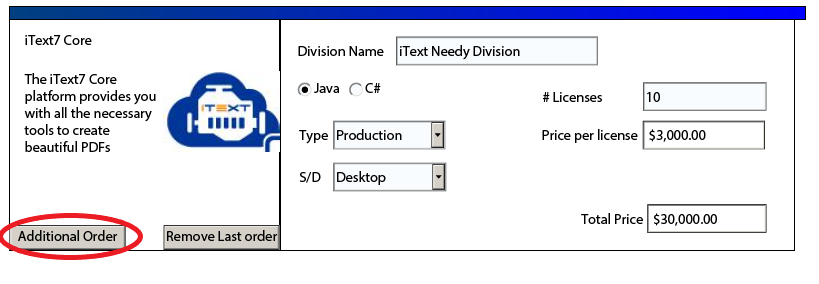
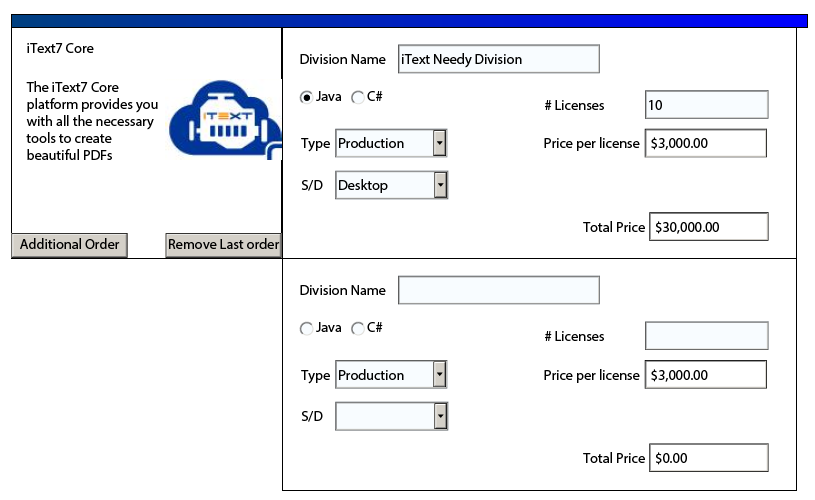
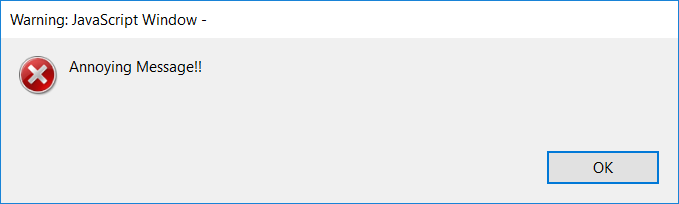
Pop-up Messages
Pop up messages can be called anytime JavaScript is executed, for example at load, a button, when a field is calculated, etc.
Modifying the XFA
Modifying the JavaScript happens in the template branch of the DOM. There are three basic steps to modifying the XFA document:
- Extract the XFA XML DOM.
- Modify the DOM
- Write the DOM back to the PDF
Extract the DOM
The XML is stored in a w3 DOM Document Object (org.w3c.dom.Document) which can be extracted using the following code:
PdfReader reader = new PdfReader(inputFileDir + "invoice.pdf");
PdfWriter writer = new PdfWriter(destFile);
PdfDocument pdfDoc = new PdfDocument(reader, writer);
XfaForm xfa = PdfAcroForm.getAcroForm(pdfDoc, false).getXfaForm();
Document domDoc = xfa.getDomDocument();
This pulls the DOM which can be navigated a few different ways.
Modify the DOM
Once inside the DOM any modification method will work. We'll go over two methods. The first is manually navigating the DOM. The second is using a NodeFilter.
Manual Navigation
The DOM can be navigated manually as well with the methods getNextSibling() and getFirstChild(). For example, to get to the Template node you can use domDoc.getFirstChild().getFirstChild().getNextSibling().getNextSibling().getNextSibling();.
NodeFilter
A NodeFilter is an Interface that filters out unwanted nodes. In the following example we filter out anything that isn't an amount field:
public class CalcCheck implements NodeFilter {
@Override
public short acceptNode(Node n) {
try {
if (n.getLocalName().equalsIgnoreCase("calculate")) {
if(n.getParentNode().getAttributes().getNamedItem("name").getNodeValue().equalsIgnoreCase("amount")) {
return NodeFilter.FILTER_ACCEPT;
}
}
return NodeFilter.FILTER_SKIP;
}
catch (NullPointerException e){
return NodeFilter.FILTER_SKIP;
}
}
}
Then you create a NodeIterator that allows for iterating over the accepted nodes:
public NodeIterator findCalc(Document doc){
Node first = doc.getDocumentElement();
DocumentTraversal docT = (DocumentTraversal) doc;
return docT.createNodeIterator(first, NodeFilter.SHOW_ALL, new CalcCheck(),true);
}
Write the DOM
Writing the DOM doesn't change based on how the DOM was modified. The DOM needs to be replaced into the XfaForm and the XFA form needs to written back into the PdfDocument. Finally the document needs to be closed:
xfa.setDomDocument(domDoc);
xfa.write(pdfDoc);
pdfDoc.close();
Examples
Change the Calculate field with a Node Filter: Java or .NET
Modify the JavaScript message manually: Java or .NET
Remove the JavaScript message manually: Java or .NET
Conclusion
The biggest issue with modifying the XFA document is that because of the flexibility of the embedded JavaScript along with the different possibilities on creating fields it is difficult to automate the fixing of files. This guide relies on some internal knowledge of the XFA structure along with the specific changes that are being made. And while a specific change might fix one file, the same issue in a different PDF might not be fixed with the same solution.
After reading all of this you might be thinking:
When would I need to do this?
This is generally only required when there is no control over where the XFA document comes from, otherwise it would be easier to modify it in a prefilled document.
Should I still be making XFA documents?
There are still pros and cons to making XFA documents, while generally it should be avoided if a system is in place built around XFA Forms then it might make sense. It's important to remember that XFA Forms are not PDF 2.0 and require knowledge of JavaScript and XFA documents.
Is there an alternative?
If you want a way to process dynamic data and output as PDF then iText DITO is the alternative you're looking for. iText DITO is iText's low-code document generator that simplifies the process of creating and maintaining data-driven forms and templates.
You can learn more about iText DITO in this article, or by visiting the product page.