See the recording our webinar done on March 22nd for an in depth intro with some of iText's developers.
Introduction
pdfHTML is an iText 7 add-on that will replace our previous XML Worker, from iText 5. This add-on gives you the ability to transform HTML and CSS content into a PDF document. In the iText 5 XML Worker the number of tags and CSS declarations supported were limited to a subset of most the frequently used tags and properties for PDF. There was no support for video, sound, control and animations etc. This focus was as much a choice as it was a necessity: the iText 5 rendering framework limited what tags and properties could be easily implemented. The rendering framework in iText 5 grew organically over the years, it was built with the static page and drawing concept of the PDF specification in mind and not the free-flowing ways of the browsers intended to paint HTML on your screen.
Now, it is time to unveil pdfHTML, the newer, sleeker XML Worker, built on the iText 7 platform. iText 7 is a rewrite from the ground-up, intended to provide the same functionality as iText 5 but with a more robust and easily extendable foundation. The renderer-framework in particular, received some attention, and now functions by building a tree of renderers and their child-renderers, and traversing it bottom-up to perform the final lay-out operations. This approach is much better suited to dealing with HTML to PDF conversion than the old model in iText 5, and allows us to easily implement future support for tags and CSS properties.
Like XMLWorker, pdfHTML is designed to work straight out of the box, no customization or configuration necessary. Just feed the HTML and any resource into the convertor and the PDF rolls out, as seen in figure 1 and the code below:
ConverterProperties converterProperties = new ConverterProperties().setBaseUri(resoureLocation);
HtmlConverter.convertToPdf(new FileInputStream(HTMLSource), new FileOutputStream(pdfDestination), converterProperties);

Figure 1: pdfHTML high level flow
To illustrate, this input HTML and Css will result in this output. Like XML Worker, it is still possible for the user to define their own, custom way for parsing tags and css, but that is a more advanced topic for a different blogpost.
pdfHTML Workflow
pdfHTML works in 2 phases. In the first phase, the HTML is parsed into an internal document format. In addition to creating an hierarchical tree-structure, this step also takes care of commonly found malformed HTML, adding missing closing tags and other common mistakes. The css-sheets are parsed into an internal style-sheet as well.
In the second phase, pdfHTML walks through the tree in a depth-first manner. Each tag is processed in 2 steps: A first processing step when the tag is encountered for the first time in the walk, and a final step after all of its children have been processed. How each tag is processed depends on which TagWorker class and CssApplier class it is mapped to. During the processing the TagWorker creates an iText layout object, then processes every child, applies css using the CssApplier instance and finally returns the lay-out object to its parent. The process is visualized in figure 2 and figure 3.
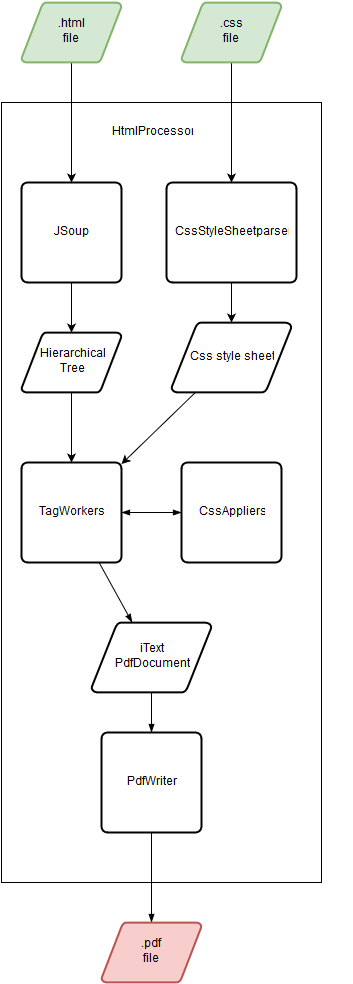
Figure 2: pdfHTML internal flow
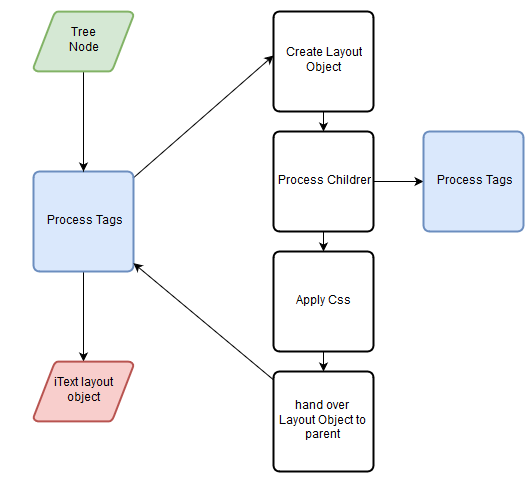
Figure 3: pdfHTML tag processing
Short Comparison to XML Worker
When comparing pdfHTML to our old solution XML Worker, pdfHTML can be seen as XML Worker++ since it has a much better support for a wider array of HTML tags and css properties. The foundation of iText 7 is also better suited to any updates, changes and patches down the road. While there will not be a lot of difference in output when processing simple HTML and css, XML Worker quickly stumbles when confronted with more complex structure or certain css properties. Examples where pdfHTML offers more than XML Worker: Borders on non-table elements, quality on table elements, handling of Arabic and other right-to-left scripts, support of responsive design through media queries, and more.
In conclusion
iText 7 add-on pdfHTML is the successor to the old iText 5 XML Worker. Like its predecessor, it provides you with a powerful tool for transforming HTML and accompanying CSS into beautiful PDFs using a broad spectrum of css properties, even more than XML Worker, while maintaining the ease of use and extensibility of the former.
Interested in trying it yourself? Download our Free Trial and get started today.


