
The latest 7.1.11 release of the iText Suite included a major update to our most popular open source add-on, pdfHTML. Now at version 3.0.0, this latest version brings some significant improvements and changes. For those unfamiliar with our HTML to PDF converter, in this article we’ll be taking a closer look at pdfHTML, its history within the iText PDF SDK, and what pdfHTML 3.x offers over previous versions.
In the beginning
The roots of pdfHTML stretch back to iText 1.x where we introduced the HTMLWorker class. This was intended as a way to convert small, simple HTML snippets into iText objects, offering an easier way to style content. If you want to make a lot of font, font style and other property changes, it’s more convenient to start from a rich text HTML snippet rather than doing it all manually via the API. However, HTMLWorker was never meant to convert complete HTML pages to PDF, yet that was how many developers tried to use it. This led to some frustration because HTMLWorker didn’t support every HTML tag, didn’t parse CSS files, and so on. To avoid this frustration, the HTMLWorker class was deprecated many years ago.
In 2011, we released XML Worker as a generic XML to PDF tool, built on top of the then current version of iText: iText 5/iTextSharp. The focus of XML Worker was on extensibility rather than being an out-of-the-box HTML-to-PDF converter, and developers could use an implementation to convert XHTML (data) and CSS (styles) to PDF, mapping HTML tags such as <p>, <img>, and <li> to iText 5 objects such as Paragraph, Image, and ListItem. However, XML Worker didn’t accept plain HTML, you had to provide XHTML instead. For instance: a single <br> wasn’t allowed in your HTML; you needed to have a <br />, all tags needed to be closed and nesting of tags needed to be done correctly. To solve this problem when confronted with incomplete HTML syntax, we advised the use of an HTML parser such as jsoup to tidy up the HTML before converting it to PDF with XML Worker. We know many developers who used XML Worker in combination with jsoup as an HTML2PDF converter.
XML Worker wasn’t a URL2PDF tool though, and expected predictable HTML created for the sole purpose of converting that HTML to PDF. To clarify, it was designed to work with static HTML content, as opposed to dynamic (e.g. JavaScript). A common use case was the creation of invoices. Rather than programming the design of an invoice in Java or C#, developers chose to create a simple HTML template defining the structure of the document, and some CSS defining the styles. They then populated the HTML with data and used XML Worker to create the invoices as PDF documents, throwing away the original HTML.
XML Worker did suffer from the limitations of being based around iText 5 though. iText 5 was designed as a tool to produce PDF as fast as possible, flushing pages to the OutputStream as soon as they were finished, and its layout engine was a top-to-bottom, left-to-right line-based approach which did not lend itself well to tasks such as HTML conversion. This, and several other design choices that made perfect sense when iText was first released in the year 2000, were still present sixteen years later. In addition, many developers simply wanted to just convert HTML to PDF, instead of working with a fully-fledged generic XML framework. It was clear that if we really wanted to create a great HTML to PDF converter, we would first have to rewrite iText from scratch. So, this is what we proceeded to do.
Out with the old, in with the new
The 2016 release of iText 7 brought significant changes. In addition to completely rewriting iText from the ground up, we also announced that in future, additional functionality would be added to iText in specific “add-ons” in order to keep the Core library clean and lean. To that end, we introduced the pdfHTML add-on which focused specifically on HTML to PDF conversion, leveraging the underlying improvements of iText 7. It also integrated jsoup, meaning you didn’t need to call it separately and so all HTML would be cleaned up before converting to PDF.
iText 7’s layout engine and the new Renderer framework was now designed around a block-based approach, taking its inspiration from HTML. When a document is created with iText 7, a tree of renderers and their child-renderers is built. The layout is created by traversing that tree, an approach that is much better suited to dealing with HTML to PDF conversion. The iText objects were completely redesigned to better match HTML tags and to allow setting styles “the CSS way.”
As an example, in iText 5, you had a PdfPTable and a PdfPCell object to create a table and its cells. If you wanted every cell to contain text in a font different from the default font, you needed to set that font for the content of every separate cell. In iText 7, you have a Table and Cell object, and when you set a different font for the complete table, this font is inherited as the default font for every cell. That was a major step forward in terms of architectural design, especially if the goal is to convert HTML to PDF.
From the very first release of pdfHTML, it offered some significant advantages over XML Worker, such as:
- Improved performance and reliability, even when using invalid HTML
- Support for RTL and complex scripts out of the box without additional effort
- Support for @media, initial support for @page rules
- Support for base64-encoded images
- Better CSS positioning support
Other features included extending pdfHTML's functionality with custom tags, to insert barcodes into documents or add custom CSS behavior for example. Being designed to work specifically with iText 7 meant other possibilities, such as using it with pdfCalligraph to convert HTML with text in global languages and writing systems, while ensuring that it would be rendered in your PDF correctly.
Later releases also brought many features and improvements including support for more HTML tags, improvements to CSS handling, support for SVG images, and also support for the HTML lang attribute to help with PDF/UA compliant document creation, and much more. For a complete list, check out our Releases page.
Now, in 2020 we’ve released pdfHTML 3.0 which adds:
- Support for the line-height property for inline-level elements as well (in addition to improved support for block-level elements)
- Improved line height calculation differences between browsers and PDF rendering
- Improved creation and/or merging of outlines
- Support for widow and orphan properties
A significant difference for pdfHTML 3.0 is the improved line height calculation, which means this is a breaking change. However, if want to maintain the behavior of pdfHTML 2.x with pdfHTML 3.x then don’t worry! We’ve provided a nifty code example on our Release page to help you do this.
While pdfHTML is still not a URL2PDF tool, it isn’t designed to be. Nevertheless, it has several advantages over XML Worker when it comes to dealing with dynamic HTML content, such as the new widow/orphan control. If you need to process dynamic HTML that uses JavaScript, an option would be to use a browser engine (such as WebKit or Gecko) to interpret the JavaScript first, giving you HTML that can be rendered by pdfHTML (if you need some pointers on how you would go about this, stay posted...)
Demonstration time!
For those developers already using pdfHTML, we thought it would be helpful to put together a quick comparison between the previous release, pdfHTML 2.1.7, and the new pdfHTML 3.0.0. It should be noted that in all these comparisons, no configuration has been done to modify the HTML to PDF transformation: we're just looking at the default output of a quick and dirty conversion.
First, we have a screenshot of our example HTML page displayed in a web browser:
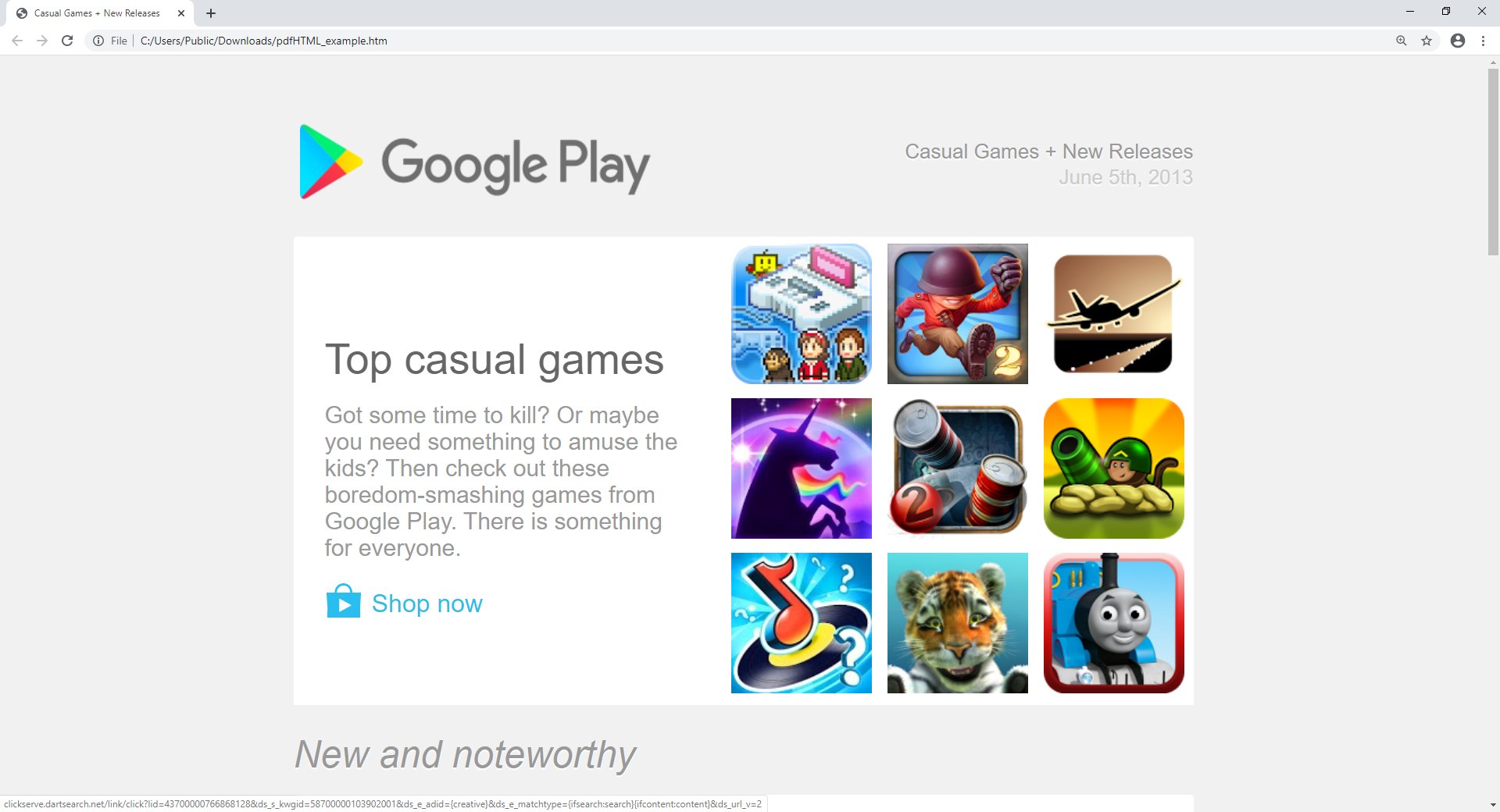
This example contains a number of different HTML elements, such as a table with a grid of images on the right, different font sizes and colors, plus a couple of other images (such as the logo at the top of the page).
Just for fun, let’s take a look at how the old XML Worker for iText 5 would convert this into a PDF:
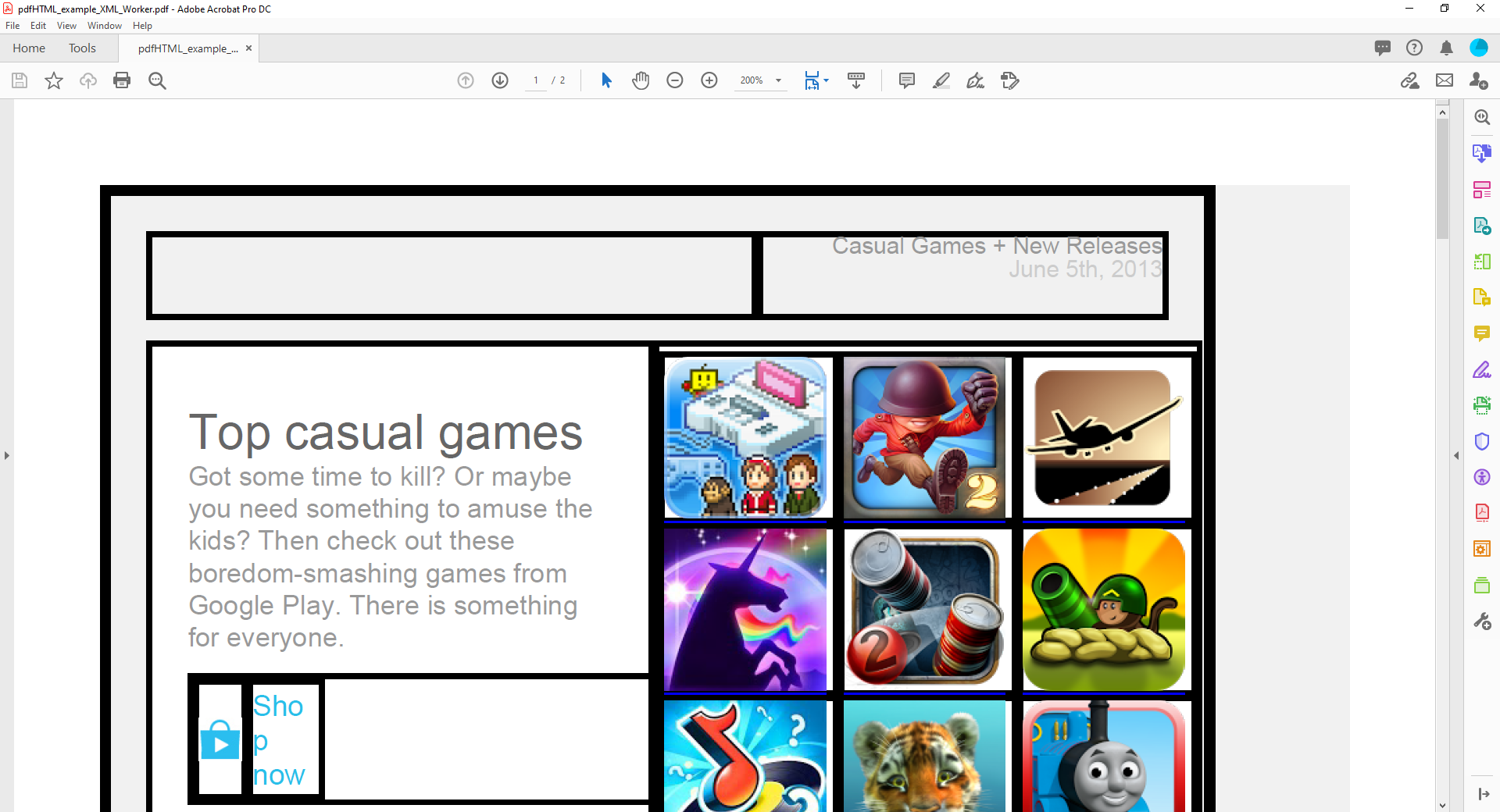
Well, that doesn’t look too good. The logo has disappeared entirely, and the table has had some rather ugly borders applied throughout which has mangled the cell containing the “Shop now” text. Still, XML Worker was put out to pasture a fair few years ago now. Let’s move on to something more modern.
Below are screenshots of the resulting PDF files produced by pdfHTML 2.1.7 and pdfHTML 3.0.0:
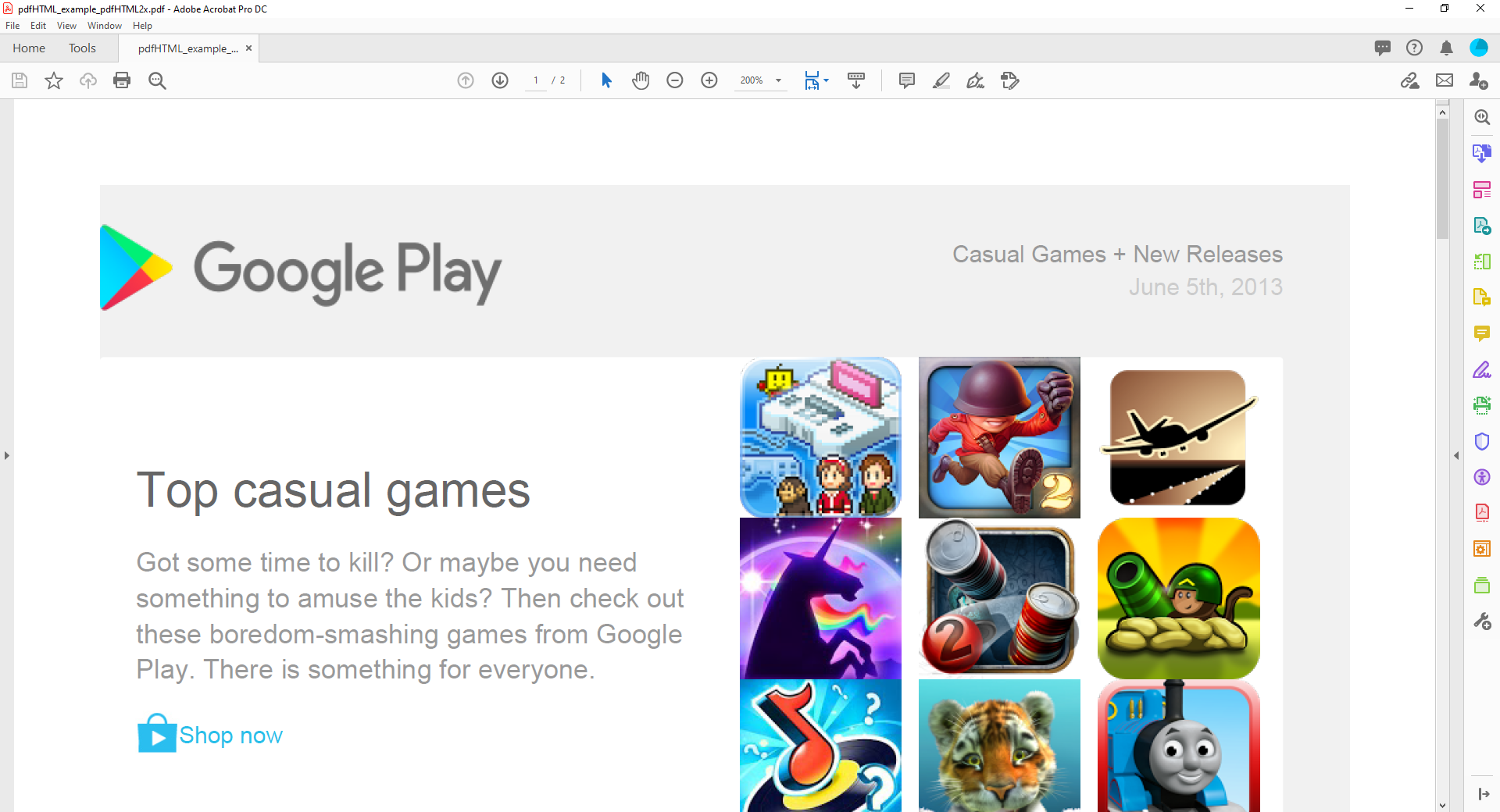 | 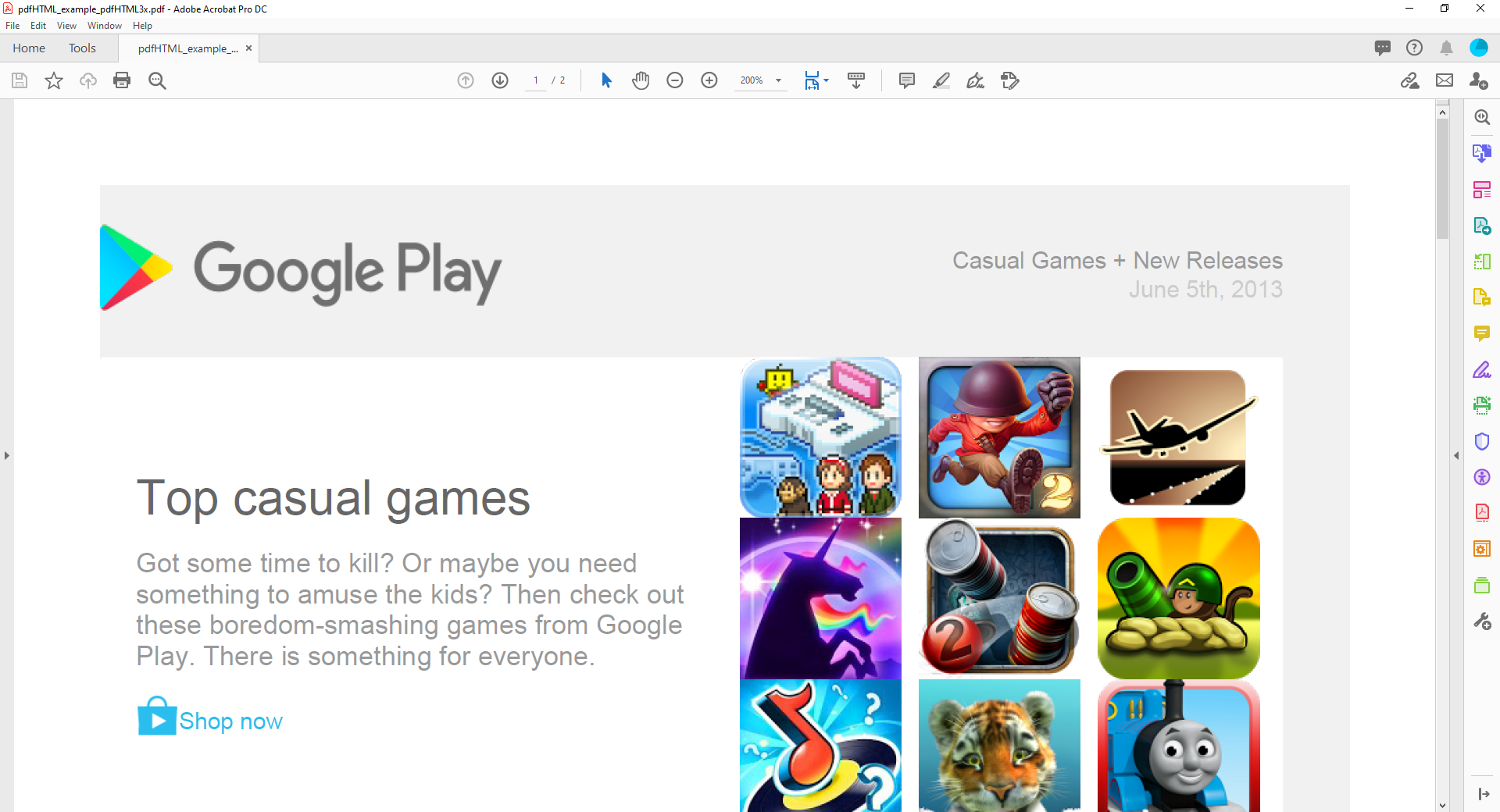 |
Straight away, we can see pdfHTML 2.x enables a much closer conversion. The table borders are gone, no images appear to be missing, and things are formatted much closer to the original.
However, taking a closer look at the pdfHTML 2.x output shows a discrepancy in the line height, most easily visible in the space between the title and the paragraph of text below it. If we compare to the output from pdfHTML 3.x, we can see that thanks to the improved line height calculation available in pdfHTML 3.x, the text is rendered much closer to the original HTML file.
To show this difference more clearly, we’ve prepared a quick example using the line-height property to change the spacing between different lines of text. This is our source HTML displayed in a browser window:

And here is a side-by-side comparison with pdfHTML 2.x on the left, and pdfHTML 3.x on the right:
 |  |
As you can see, the pdfHTML 3.x output is exactly the same as the source HTML thanks to the improved line-height handling.
It’s important to note that these examples only show what you will get without configuring the output. If you're prepared to put the work in, pdfHTML offers a great deal of configuration over the conversion and the resulting PDF.
Remember, pdfHTML is available under our dual licensing terms. If you’re unable to comply with the AGPL and want to give pdfHTML a try, you can get a 30-day free trial of iText Suite, which comprises iText 7 Core, pdfHTML and all the other iText 7 add-ons.
Meanwhile, for those of you still using iText 5/iTextSharp, this is just a taste of what you’ve been missing out on! Of course, better HTML to PDF conversion is just one of the many reasons why you should be using iText 7, check out the Features comparison to learn more.


