
Once upon a time, somewhere in Europe there was a tiny kingdom. Despite its small size, it held the dubious distinction of possessing more government departments per square meter than anywhere else in the world. One day, government ministers proudly announced they had decided to add yet another department to the list, which would officially be known as “The Agency for Administrative Simplification”.
This might sound like the beginning of a story from a children’s book, but it’s no fairytale. The year was 1998, and the country was Belgium, which is renowned for its complex system of government, and the associated bureaucracy that comes with it. All this meant there was a real need for a dedicated agency to reduce the amount of administration and paperwork required by Belgian companies and individuals. What’s more, the pain they tried to solve is one that many governments and businesses worldwide recognize all too well.
Reality versus the fairytale
Of course, the “Agency for Administrative Simplification” is just a direct English translation of the Dutch “Dienst Administratieve Vereenvoudiging” (“DAV”), but the description is an accurate one. Originally established to propose methods of simplifying the administrative complexity and accompanying costs incurred by companies, in 2003 this remit was extended to include administrative matters relating to Belgian citizens. As part of this simplification process, the recent launch of the Database of Civil Registry Records (DABS) digitally transformed the process of issuing birth, marriage, adoption, change of nationality, and death certificates, a process that had remained unchanged since the time of Napoleon.
The aim of the DABS project was to centralize all the citizen certification processes described above, completely replacing the inefficient and expensive paper-based process, By storing the information in a single database, it would be accessible by all local authorities saving both time and money.
To do this, they used iText's PDF software (specifically iText DITO), a low-code PDF template designer and generator, to take data from their citizen information database and generate digital-first certification. Using iText DITO's visual editor to design templates for the required PDF documents, it was easy to unify certificates into a standardized format, while also customizing them for each of the almost 600 local authorities across Belgium. In addition, iText DITO makes it simple to update and revise certificate templates as required (e.g. to account for changes in the law). With traditional hardcoded templates this would be much more difficult to achieve.

If you're interested in learning more about how iText DITO helped the digital transformation of the Belgian civil registry, check out our deep dive into how this was achieved.
Introducing our heroes: OCR and PDF
iText is a developer of powerful PDF solutions. In addition to high-convenience, low-code products like iText DITO, it also offers the award-winning iText 7 Suite, which allows the development of scalable workflows for the generation, manipulation and processing of PDF documents (with iText 7 Core). The iText 7 Suite includes all the available iText 7 Core add-ons which enable dedicated features, one of which is optical character recognition (with iText pdfOCR) to recognize and extract text from scanned documents.
iText pdfOCR allows you to automate the processing of scanned documents and images and is able to recognize and extract text in over 100 different languages with support for custom dictionaries and training models for nonstandard languages, character sets and glyphs. Built around the proven and powerful open-source Tesseract 4 OCR engine, it offers a simple, yet flexible API which even allows developers to make use of custom OCR engines as required, without needing to modify the workflow.
The output from iText pdfOCR can be configured to be either text, a layered PDF with recognized text and image data contained in separate layers, or a flattened PDF with the layers merged. It generates PDF 1.7 compliant documents, and also supports the PDF/A-3u standard for long-term archive storage.
There are many OCR use cases where the benefits of using iText in a digitally-transformed document workflow are clear to see. The DAV were fortunate in that they already had their data in a database, yet businesses and governments worldwide are struggling with enormous collections of physical typewritten paper or scanned documents, all containing potentially crucial data. Getting this data into a digitally accessible format usable with other IT platforms and databases invariably results in unnecessary manual work and administrative overload.
The beauty of using a tool like iText pdfOCR is the text recognition process can be easily automated and integrated into your document workflow; allowing for large-scale document processing, whether simply for archiving purposes, or to enable data extraction from the documents for further processing and transformation.
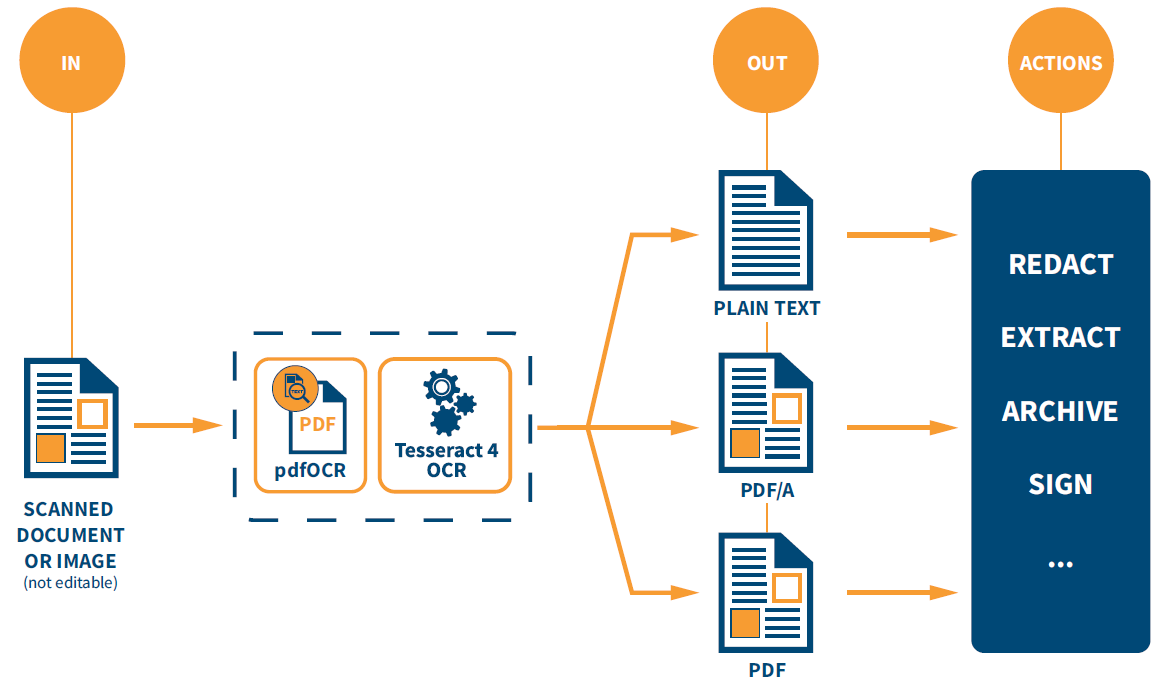
Thanks to automatable OCR solutions powered by iText however, data in scanned documents can be easily recognized, extracted, and repurposed into new workflows. You can also make use of low-code tools like iText pdf2Data or iText DITO to assist with data extraction and document generation, or use iText 7 Core and its add-ons to achieve advanced tasks such as secure content redaction, generating multilingual documents using complex script rendering, HTML to PDF conversion, securing and digitally signing documents in accordance with the PAdES standard, or simply archiving documents as searchable, accessible PDFs.
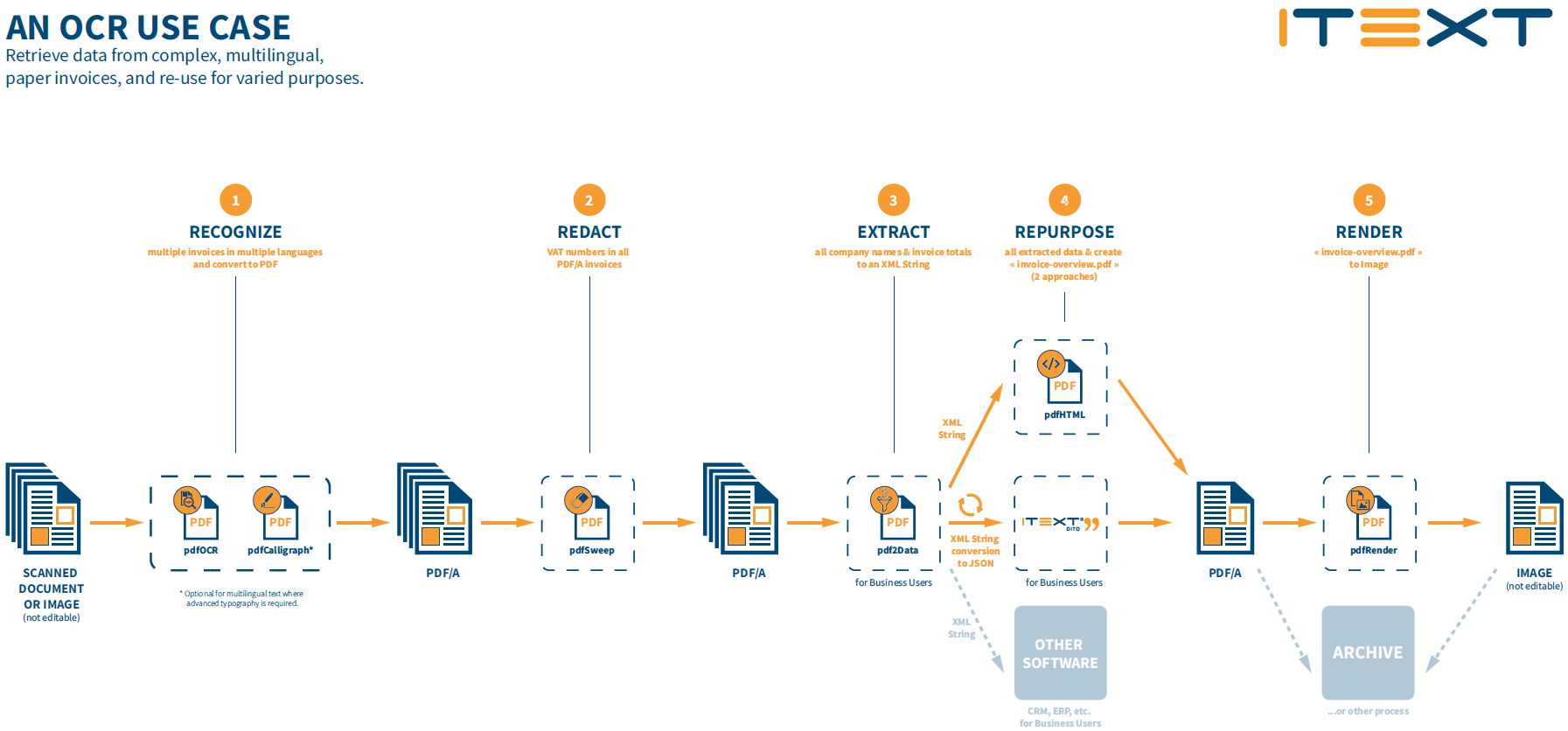
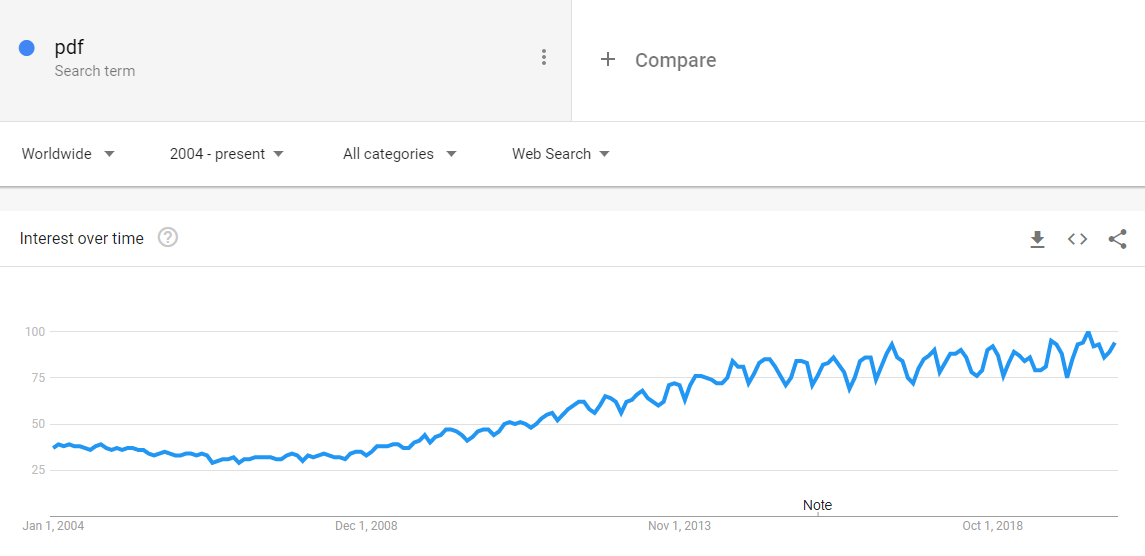
The PDF format is ideal for these purposes. Far from being just a digital representation of a printed document, it’s a versatile and extensible data container format and is the de-facto standard for exchanging documents and information. Since it was invented back in 1993, the format has grown to encompass a unique set of capabilities, and data from Google Trends shows it's more popular on the web than ever.
The moral of the story
Countless industries can benefit from automated OCR processing in their workflows, such as banking, legal, healthcare, manufacturing etc. Similarly, government departments may have literal mountains of paperwork relating to government policies, citizens’ personal information, and other data that needs to be processed from masses of printed documents.
Governments and corporations are sitting on goldmines of inaccessible data locked away in documents. In a post-COVID-19 world, the digitalization of document workflows is more important than ever, and the potential insights and knowledge are simply staggering. Time to unlock that hidden potential!
This article was adapted and expanded from our featured article in the AIIM e-book "Information at Work, Wherever Work Is", a compilation of articles on digital transformation from industry thought leaders.