
Introduction
Digitalization has revolutionized document management over the past few decades. An essential part of many document workflows is the conversion of paper-based documents into digital information, yet scanning documents is only one step of the process. One of the major challenges in document management is dealing with inaccessible data, data which is locked away in non-editable documents. You might think that by scanning a document containing printed text it would be possible to select and edit the content, but your supposedly digital document is actually just a scanned image of its content. Image-only or scanned PDFs are not “true” or digitally created PDFs, and therefore cannot be edited or searched. Until fairly recently, such documents would have to be transcribed by hand in order to get access to this data, but optical character recognition (OCR) provides a way to automate this process.
Introducing iText pdfOCR
One of the most common use cases for OCR is to produce documents which can be searched, processed, or archived. While some word processing and PDF applications now offer OCR functionality to make PDFs editable, manually doing this for documents at the scale many of our users require would be impractical. Therefore, we’re proud to announce the iText pdfOCR add-on, our latest addition to the iText 7 PDF SDK. iText pdfOCR offers iText Java and .NET developers a way to programmatically recognize text in scanned documents by utilizing the proven and powerful open-source Tesseract 4 OCR technology.
Like Tesseract, iText pdfOCR is provided as open source (Java and .NET GitHub repositories), and it offers a simple, yet flexible API that has been designed to allow developers to specify the use of different OCR engines. For now, however, it’s built around Tesseract, since it’s a popular and widely-used OCR engine which was originally developed by HP in 1985 and open-sourced in 2005. Since 2006, its development has been sponsored by Google and has undergone significant development, with support for text recognition in over 100 languages, custom dictionary support, and training models for nonstandard languages, character sets and glyphs. An important addition in version 4 is the utilization of a Long Short-Term Memory (LSTM) neural network to improve its speed and accuracy of text recognition.
Among the capabilities iText pdfOCR offers on top of Tesseract though is the ability to generate PDF 1.7 documents, and it also supports PDF/A3-u output for archiving. Not to mention, if you want to take advantage of capabilities provided by other OCR engines, you can configure the API to use a different OCR engine for recognition. As noted, iText pdfOCR is available under the terms of the open-source AGPL license, or can be used commercially with an iText 7 Core commercial license.
How it works
Simply pass to iText pdfOCR an image, or list of images containing text to be recognized. iText pdfOCR accepts input from any image format supported by iText, though if your document is a PDF you can simply use iText 7 Core to extract the images containing the text you need to access.
The output can be configured to be text-only, a PDF consisting of separate layers for the source image data and a layer containing all recognized text, or as a flattened PDF with the layers merged. If you need documents to be suitable for long-term archive storage, then the support for PDF/A-3u output is an added bonus.
Code examples
In our first example, we’ll demonstrate how to OCR an image to produce a PDF/A-3u compliant document:
NOTE: Don't forget to specify the path to your local Tesseract Data files using TESS_DATA_FOLDER in the code below. You can always find the most accurate trained LSTM models here.
By default, recognized text will be merged into your output file, but you may want to keep this information separated. To do this, you use the OcrPdfCreatorProperties (Java/.NET) class to define:
- If you want a separate text layer (either of the following two options will trigger the creation of a text layer)
- If you want a separate image layer
The following example uses all these options to recognize text in an input JPG, and produce a PDF with text rendered in red in a separate layer:
Since iText pdfOCR is based on Tesseract 4.1 a large number of languages and scripts are supported. You can specify the languages you want to OCR (Java/.NET), and the path to the TESS_DATA_FOLDER with the Tesseract4OcrEngineProperties (Java/.NET) class. Training data and custom dictionaries can also be specified if you want to recognize text in languages unsupported by the default Tesseract 4 dictionaries. If you require fonts to be rendered using advanced typography on a separate layer of your OCR document, please check out iText pdfCalligraph, an iText 7 add-on to easily support global languages and writing systems.
More examples, FAQs and related information can be found on the iText Knowledge Base.
Use cases
By using iText pdfOCR you can generate PDF documents which are both searchable and archivable, and compliant with the PDF/A-3u archiving standard. These documents can also be secured and digitally signed, since digital signatures in accordance with the PAdES (PDF Advanced Electronic Signatures) standard are supported in the PDF/A specification as of PDF/A-2. Alternatively, if you simply want to extract the text from scanned documents it can also output the recognized text as a file.
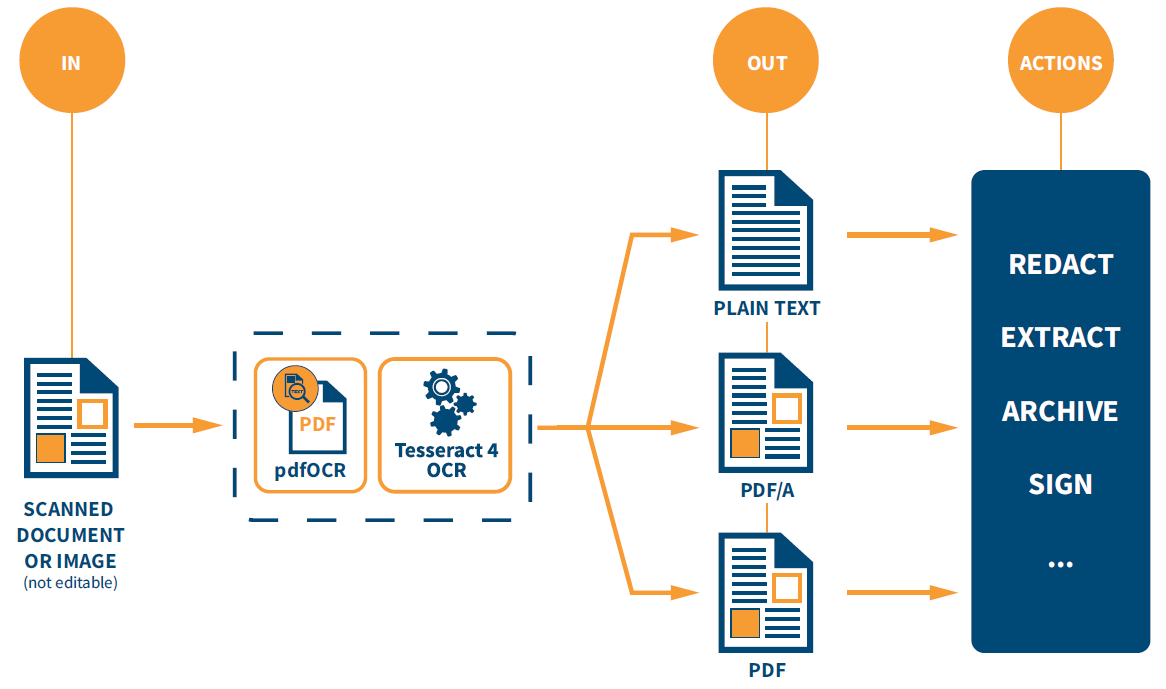
Yet that’s not all, as since it’s integrated into the iText 7 SDK, you can also use other iText 7 components to perform additional processing. Whether you need to extract images and data from your documents, perform secure content redaction, or even use the data to generate multilingual documents, there are a multitude of possibilities which are now possible once you have an accessible, searchable PDF. For example, you could:
- extract specific information with iText pdf2Data and store it in a database, enabling further processing with other systems,
- securely redact the recognized text with iText pdfSweep,
- use the extracted text to populate PDF form fields using iText 7 Core,
- alternatively, you could merge the data into HTML templates to be converted into PDF with iText pdfHTML,
- generate PDFs which support multiple languages and writing systems with iText pdfCalligraph,
- or even a combination of all the above.
You could even use iText pdfRender to convert your final document back into an image. You might wonder why you would want to do that, but let's consider a content redaction example. You could recognize the text in an image, securely remove some text, and then convert back to an image again. Additionally, an image could be ideal if you only need to view a copy of a document, such as a preview of an archived document, or a digitally signed certificate. Images are also easy to display on mobile devices, or environments where a PDF viewer is not required.
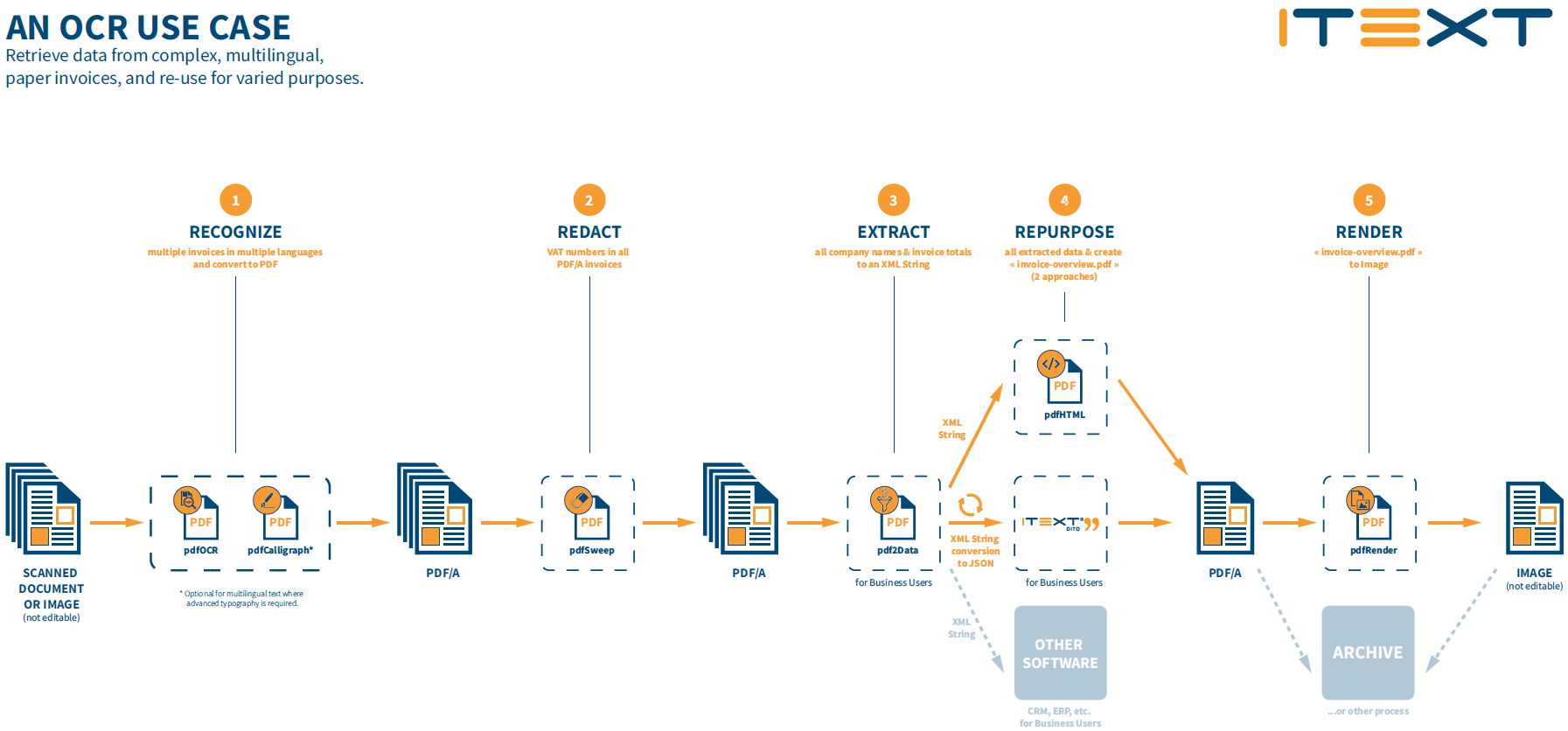
If you want a more collaborative way to repurpose the recognized text into new documents, another option might be to use iText DITO, our high-convenience PDF document generator which allows business users to play more of a role in digital document workflows. Templates can be designed and maintained using the intuitive template editor and configured with dynamic data binding and conditional formatting to inject data and configure how it is presented, all without requiring any coding skills. Then you feed your data as JSON into the iText DITO API, which combines the data and your templates to produce as many PDFs as you require. What’s more, if you also purchase a license for iText 7 Core when you buy an iText DITO license, your generated PDF documents can easily be further processed and manipulated to perform tasks such as securing your documents with encryption and digital signatures, or more low-level PDF actions like merging and splitting documents etc.
Benefits of OCR
The beauty of using a tool like iText pdfOCR is the text recognition process can be easily automated and integrated into your document workflow. This allows for large-scale document processing, whether simply for archiving purposes, or to enable data extraction from the documents for further processing and transformation. There are many industries which could benefit from automated OCR processing in their workflows, such as banking, legal, healthcare, manufacturing etc., not to mention government departments who often have literal mountains of paperwork relating to government policies, citizens’ personal information, and other data that needs to be processed from masses of printed documents.
In a post-COVID-19 world this is more important than ever. With governments worldwide implementing policies for tracking and tracing peoples’ movements, being able to process data quickly and easily such as passport scans and medical insurance certificates is essential. Add to this the various implementations of Digital Identity programs across the globe, such as the European Single Digital Gateway or Singapore’s National Digital Identity platform, and it’s clear that automating OCR into document workflows is going to be vital for governments and companies alike.


